CVAT is a free, online, interactive video and image annotation tool for computer vision.
It is being developed and used by Intel to annotate millions of objects with different properties.
Many UI and UX decisions are based on feedbacks from professional data annotation team.
Try it online cvat.org.
Our documentation provides information for AI researchers, system administrators, developers, simple and advanced users.
The documentation is divided into three sections, and each section is divided into subsections basic and advanced.
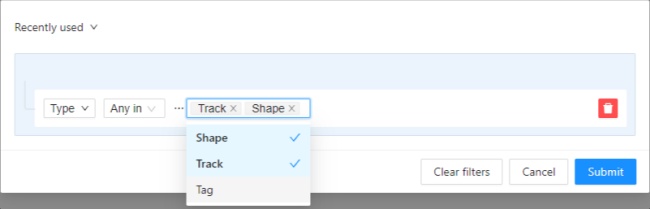
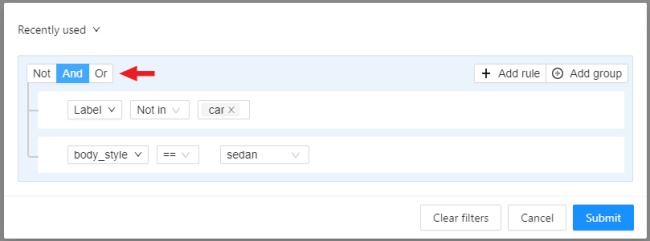
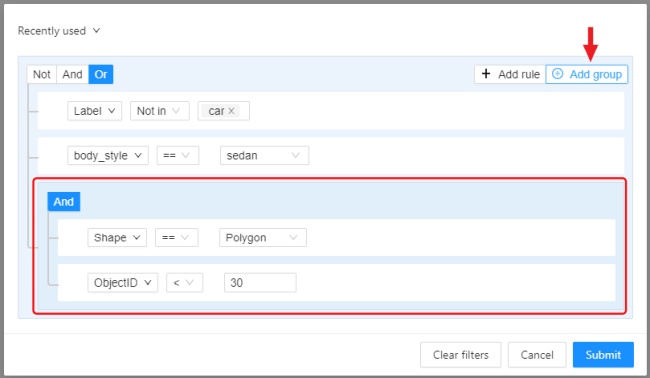
In CVAT there is the possibility of using automatic and semi-automatic annotation what gives
you the opportunity to speed up the execution of the annotation:
This section contains documents for CVAT simple and advanced users
2.1 - Basics
This section contains basic documents for CVAT users
2.1.1 - Authorization
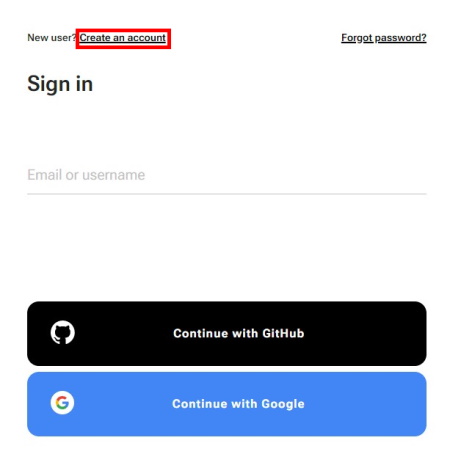
First of all, you have to log in to CVAT tool.
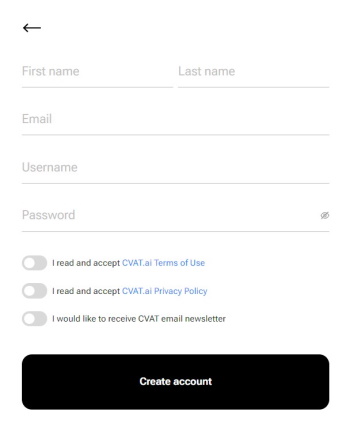
For register a new user press “Create an account”
You can register a user but by default it will not have rights even to view
list of tasks. Thus you should create a superuser. The superuser can use
Django administration panel to assign correct
groups to the user. Please use the command below to create an admin account:
If you want to create a non-admin account, you can do that using the link below
on the login page. Don’t forget to modify permissions for the new user in the
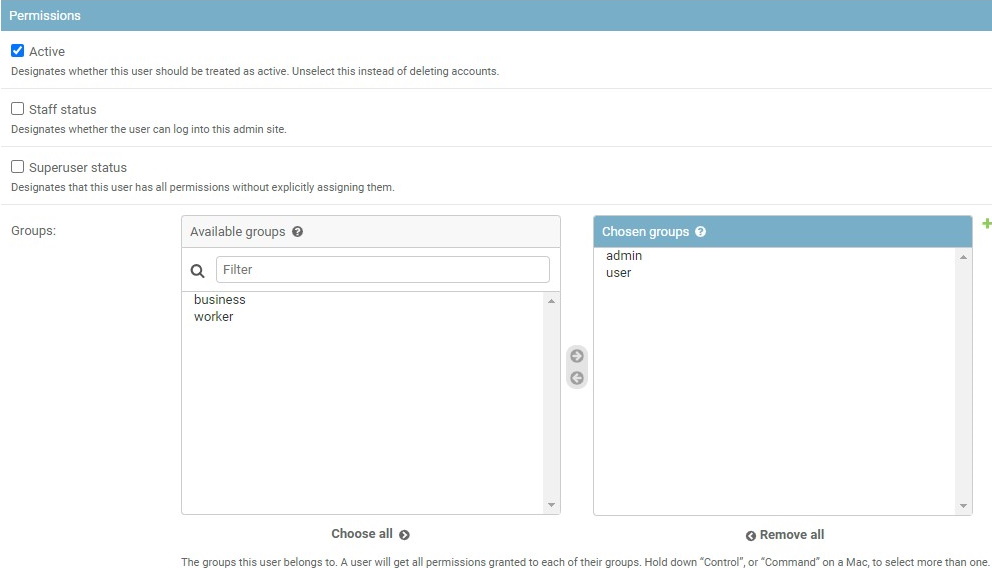
administration panel. There are several groups (aka roles): admin, user,
annotator, observer.
Control permissions of users and access to the tool.
2.1.2 - Creating an annotation task
Instructions on how to create and configure an annotation task.
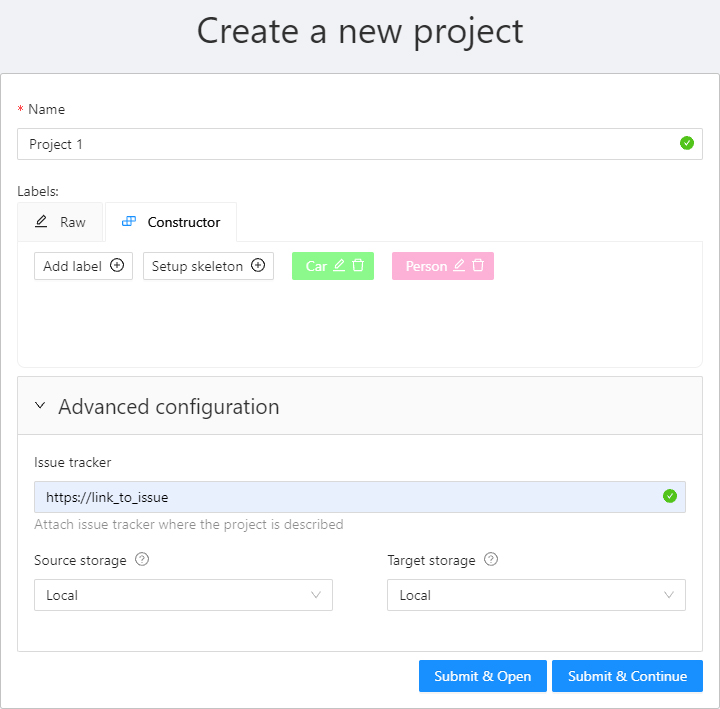
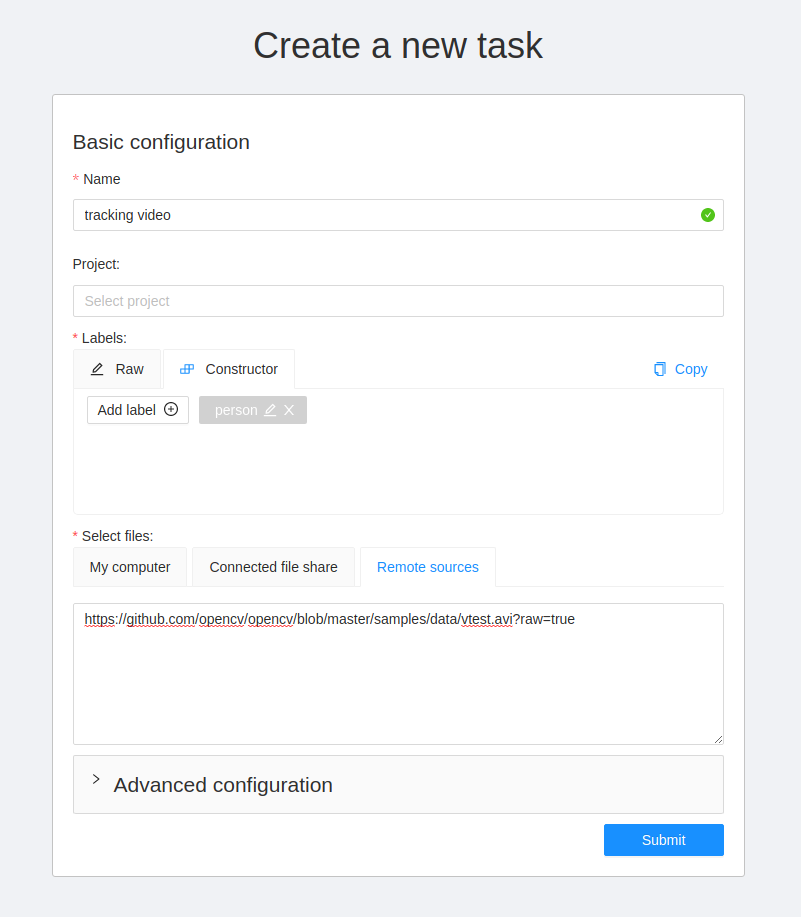
Create an annotation task pressing Create new task button on the tasks page or on the project page.
Specify parameters of the task:
Basic configuration
Name
The name of the task to be created.
Projects
The project that this task will be related with.
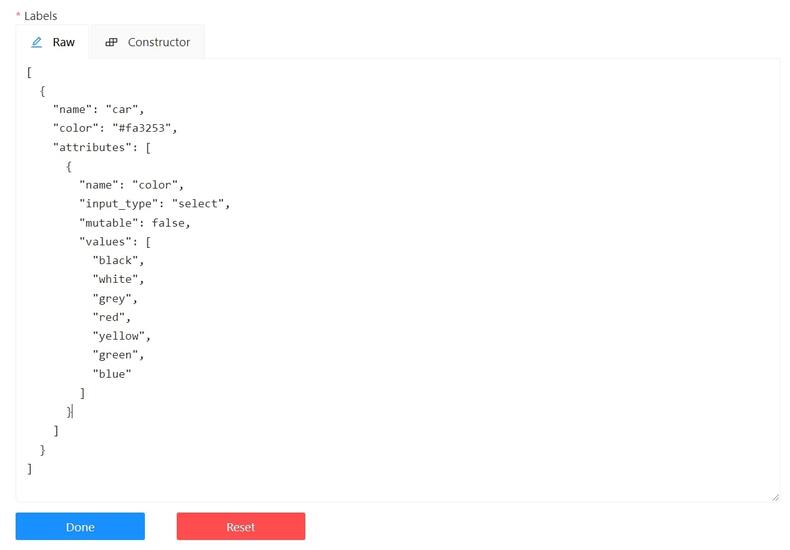
Labels
There are two ways of working with labels (available only if the task is not related to the project):
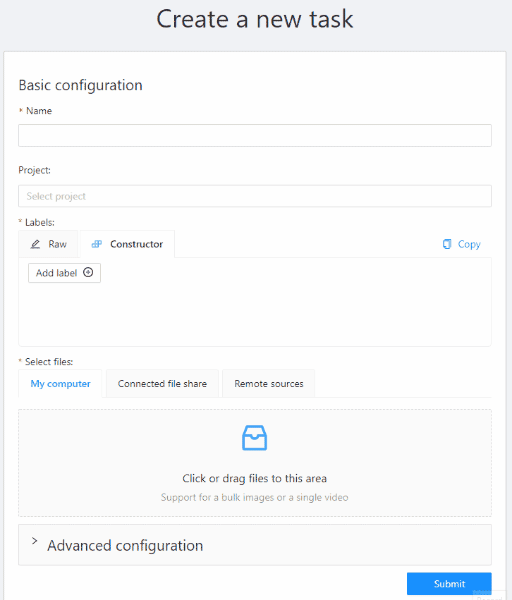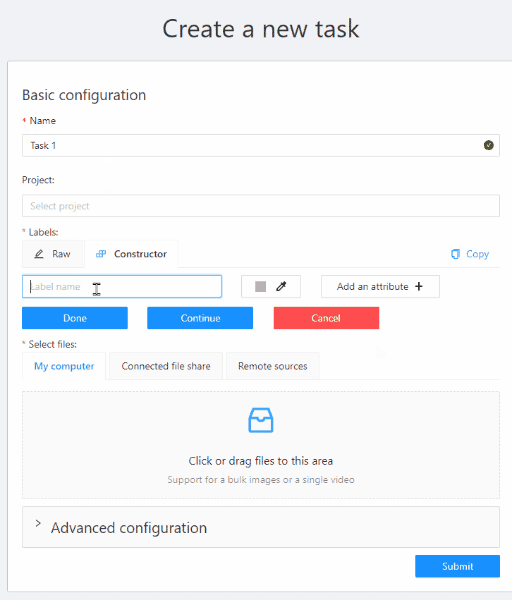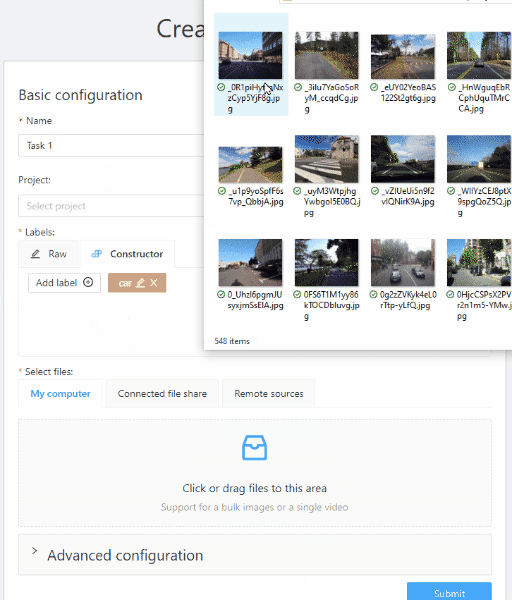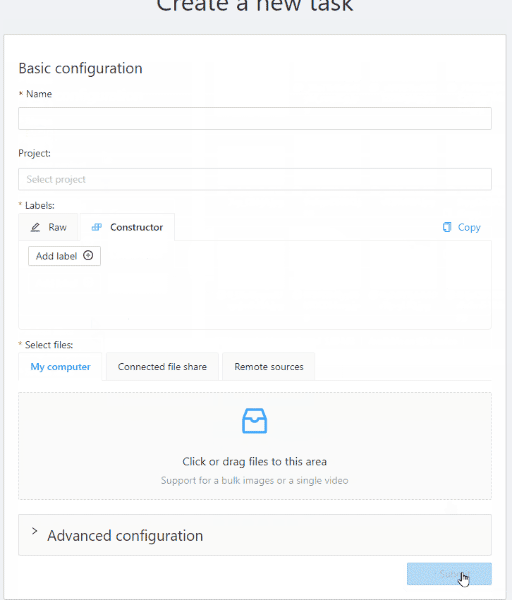
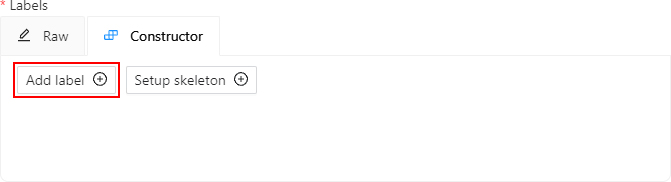
The Constructor is a simple way to add and adjust labels. To add a new label click the Add label button.
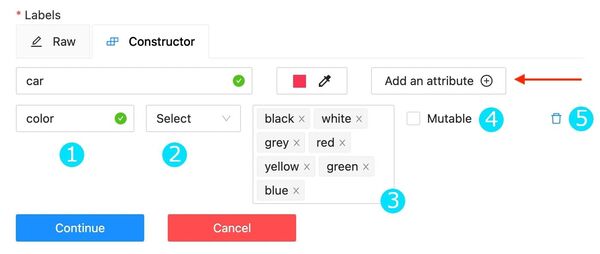
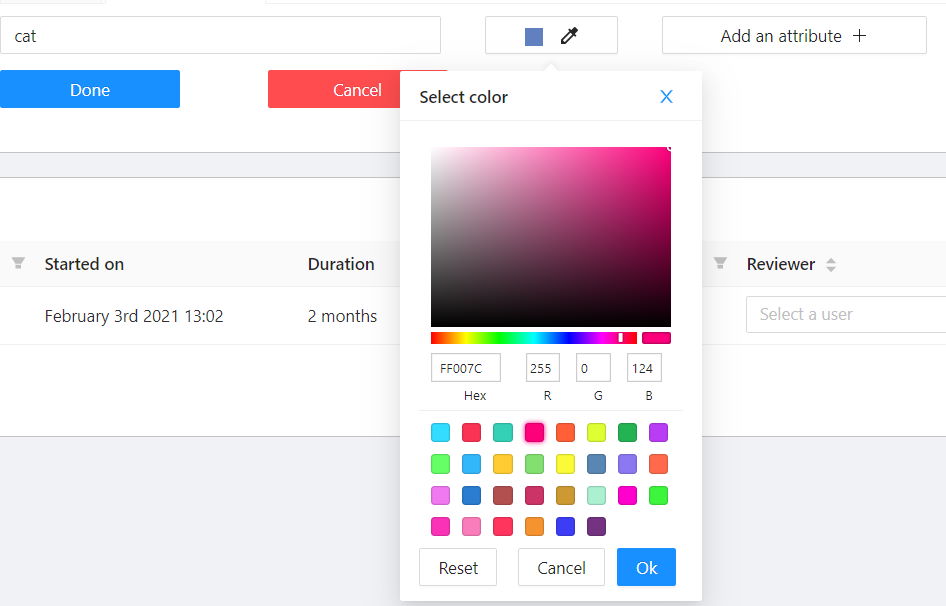
You can set a name of the label in the Label name field and choose a color for each label.
If necessary you can add an attribute and set its properties by clicking Add an attribute:
The following actions are available here:
Set the attribute’s name.
Choose the way to display the attribute:
Select — drop down list of value
Radio — is used when it is necessary to choose just one option out of few suggested.
Checkbox — is used when it is necessary to choose any number of options out of suggested.
Text — is used when an attribute is entered as a text.
Number — is used when an attribute is entered as a number.
Set values for the attribute. The values could be separated by pressing Enter.
The entered value is displayed as a separate element which could be deleted
by pressing Backspace or clicking the close button (x).
If the specified way of displaying the attribute is Text or Number,
the entered value will be displayed as text by default (e.g. you can specify the text format).
Checkbox Mutable determines if an attribute would be changed frame to frame.
You can delete the attribute by clicking the close button (x).
Click the Continue button to add more labels.
If you need to cancel adding a label - press the Cancel button.
After all the necessary labels are added click the Done button.
After clicking Done the added labels would be displayed as separate elements of different colour.
You can edit or delete labels by clicking Update attributes or Delete label.
The Raw is a way of working with labels for an advanced user.
Raw presents label data in json format with an option of editing and copying labels as a text.
The Done button applies the changes and the Reset button cancels the changes.
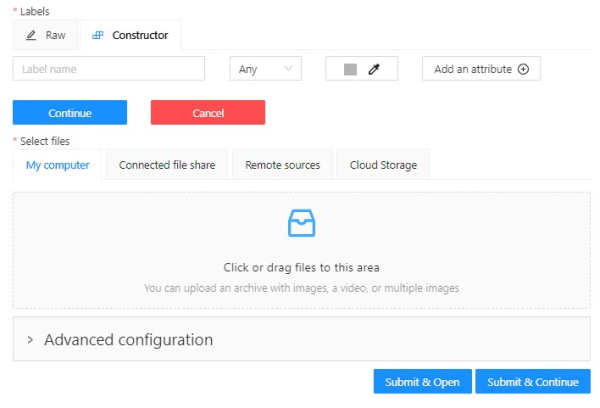
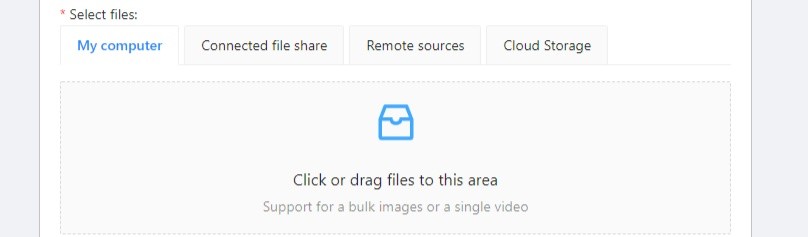
Select files
Press tab My computer to choose some files for annotation from your PC.
If you select tab Connected file share you can choose files for annotation from your network.
If you select Remote source , you’ll see a field where you can enter a list of URLs (one URL per line).
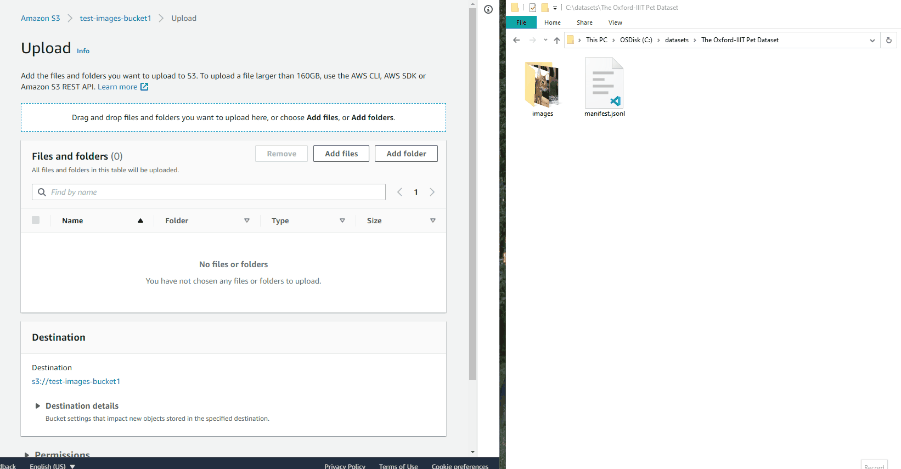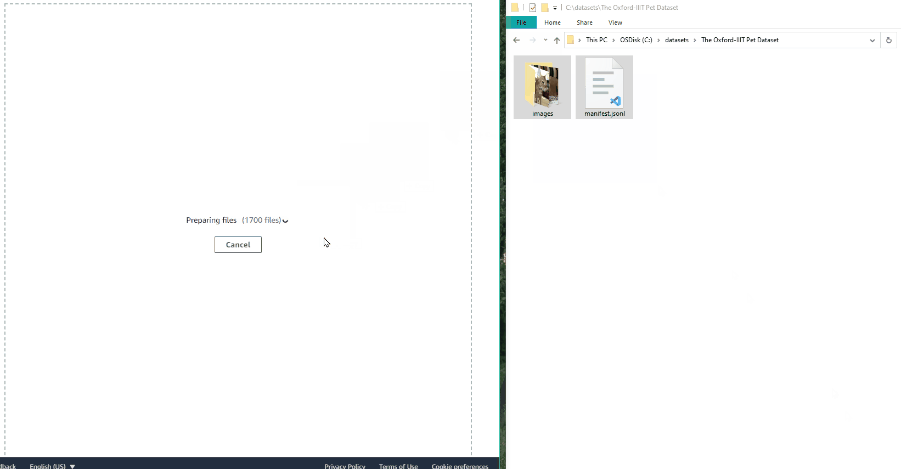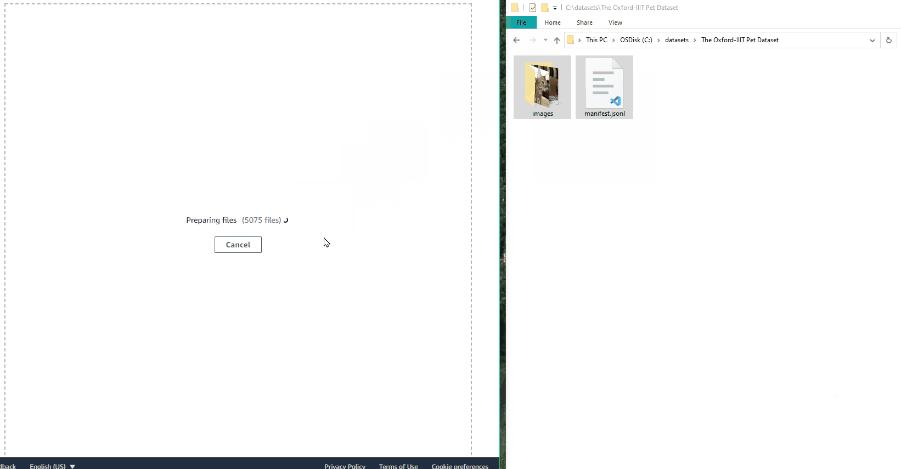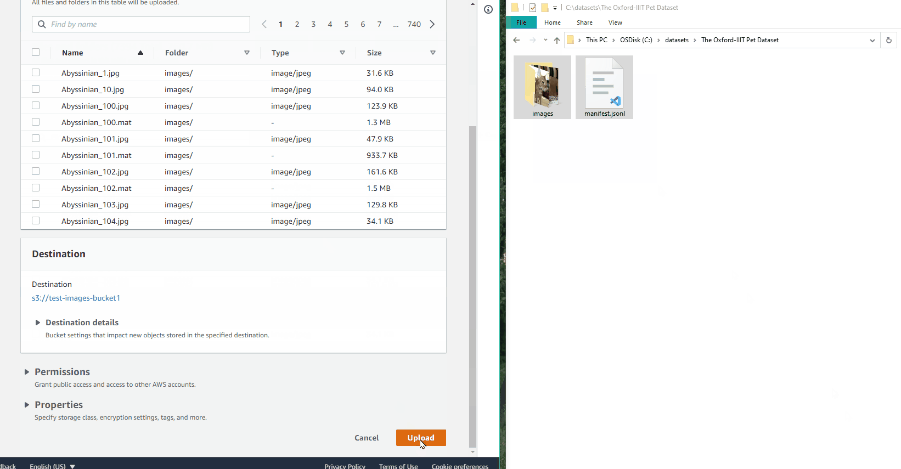
If you upload a video or dataset with images and select Use cache option, you can attach a manifest.jsonl file.
You can find how to prepare it here.
If you select the Cloud Storage tab, you can select a cloud storage (for this type the cloud storage name),
after that choose the manifest file and select the required files.
For more information on how to attach cloud storage, see attach cloud storage
Data formats for a 3D task
To create a 3D task, you must prepare an archive with one of the following directory structures:
VELODYNE FORMAT
Structure:
velodyne_points/
data/
image_01.bin
IMAGE_00 # unknown dirname,
# generally image_01.png can be under IMAGE_00, IMAGE_01, IMAGE_02, IMAGE_03, etc
data/
image_01.png
3D POINTCLOUD DATA FORMAT
Structure:
pointcloud/
00001.pcd
related_images/
00001_pcd/
image_01.png # or any other image
3D, DEFAULT DATAFORMAT Option 2
Structure:
data/
image_1/
image_1.pcd
context_1.png # or any other name
context_2.jpg
You can’t mix 2D and 3D data in the same task.
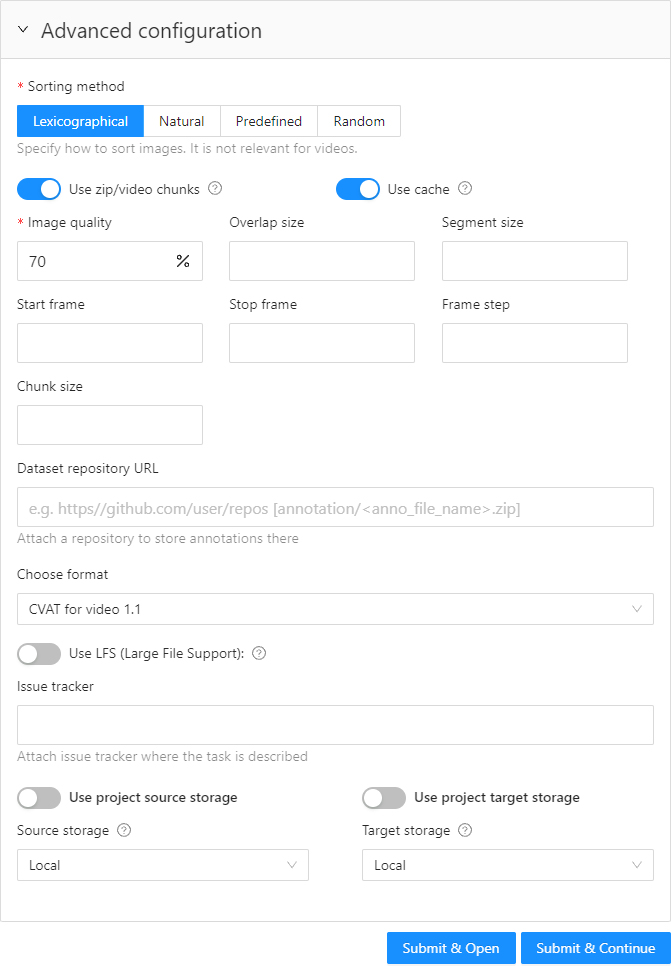
Advanced configuration
Sorting method
Option to sort the data. It is not relevant for videos.
For example, the sequence 2.jpeg, 10.jpeg, 1.jpeg after sorting will be:
lexicographical: 1.jpeg, 10.jpeg, 2.jpeg
natural: 1.jpeg, 2.jpeg, 10.jpeg
predefined: 2.jpeg, 10.jpeg, 1.jpeg
Use zip chunks
Force to use zip chunks as compressed data. Actual for videos only.
Use cache
Defines how to work with data. Select the checkbox to switch to the “on-the-fly data processing”,
which will reduce the task creation time (by preparing chunks when requests are received)
and store data in a cache of limited size with a policy of evicting less popular items.
See more here.
Image Quality
Use this option to specify quality of uploaded images.
The option helps to load high resolution datasets faster.
Use the value from 5 (almost completely compressed images) to 100 (not compressed images).
Overlap Size
Use this option to make overlapped segments.
The option makes tracks continuous from one segment into another.
Use it for interpolation mode. There are several options for using the parameter:
For an interpolation task (video sequence).
If you annotate a bounding box on two adjacent segments they will be merged into one bounding box.
If overlap equals to zero or annotation is poor on adjacent segments inside a dumped annotation file,
you will have several tracks, one for each segment, which corresponds to the object.
For an annotation task (independent images).
If an object exists on overlapped segments, the overlap is greater than zero
and the annotation is good enough on adjacent segments, it will be automatically merged into one object.
If overlap equals to zero or annotation is poor on adjacent segments inside a dumped annotation file,
you will have several bounding boxes for the same object.
Thus, you annotate an object on the first segment.
You annotate the same object on second segment, and if you do it right, you
will have one track inside the annotations.
If annotations on different segments (on overlapped frames)
are very different, you will have two shapes for the same object.
This functionality works only for bounding boxes.
Polygons, polylines, points don’t support automatic merge on overlapped segments
even the overlap parameter isn’t zero and match between corresponding shapes on adjacent segments is perfect.
Segment size
Use this option to divide a huge dataset into a few smaller segments.
For example, one job cannot be annotated by several labelers (it isn’t supported).
Thus using “segment size” you can create several jobs for the same annotation task.
It will help you to parallel data annotation process.
Start frame
Frame from which video in task begins.
Stop frame
Frame on which video in task ends.
Frame Step
Use this option to filter video frames.
For example, enter 25 to leave every twenty fifth frame in the video or every twenty fifth image.
Chunk size
Defines a number of frames to be packed in a chunk when send from client to server.
Server defines automatically if empty.
Recommended values:
1080p or less: 36
2k or less: 8 - 16
4k or less: 4 - 8
More: 1 - 4
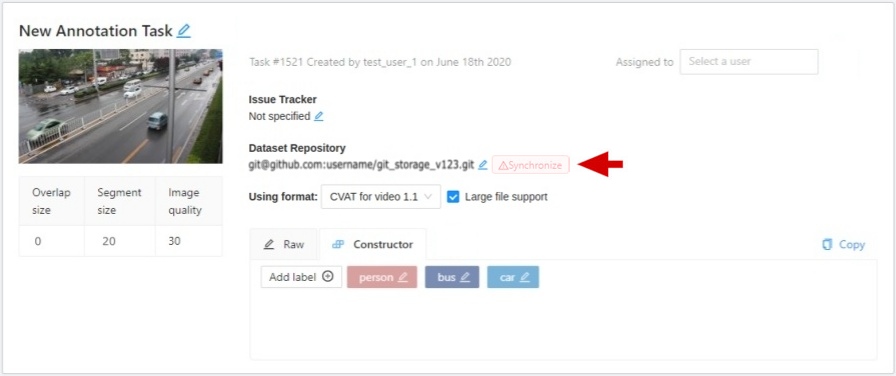
Dataset Repository
URL link of the repository optionally specifies the path to the repository for storage
(default: annotation / <dump_file_name> .zip).
The .zip and .xml file extension of annotation are supported.
Field format: URL [PATH] example: https://github.com/project/repos.git [1/2/3/4/annotation.xml]
Supported URL formats :
https://github.com/project/repos[.git]
github.com/project/repos[.git]
git@github.com:project/repos[.git]
After the task is created, the synchronization status is displayed on the task page.
If you specify a dataset repository, when you create a task, you will see a message
about the need to grant access with the ssh key.
This is the key you need to add to your github account.
For other git systems, you can learn about adding an ssh key in their documentation.
Use LFS
If the annotation file is large, you can create a repository with
LFS support.
Issue tracker
Specify full issue tracker’s URL if it’s necessary.
Push Submit button and it will be added into the list of annotation tasks.
Then, the created task will be displayed on a tasks page.
2.1.3 - Jobs page
On the jobs page, users (for example, with the worker role)
can see the jobs that are assigned to them without having access to the task page,
as well as track progress, sort and apply filters to the job list.
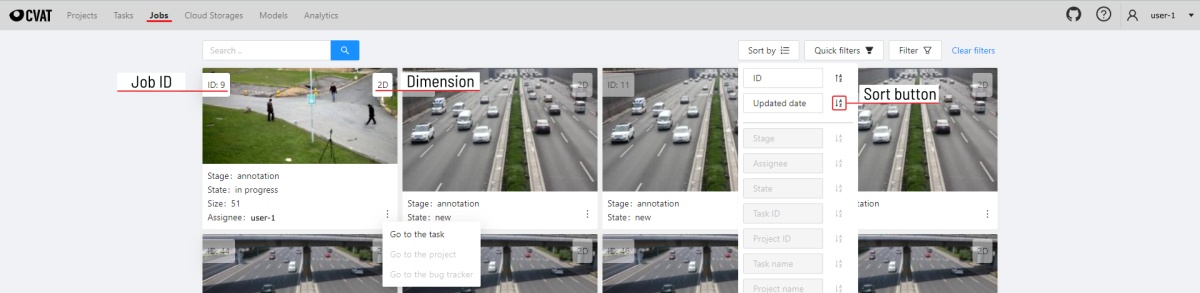
On the job page there is a list of jobs presented in the form of tiles, where each tile is one job.
Each element contains:
- job ID
- dimension 2D or 3D
- preview
- stage and state see vocabulary section
- when hovering over an element, you can see:
- size
- assignee
- menu to navigate to a task, project, or bug tracker.
In the upper right corner there is a search bar, using which you can find the job by designated user, stage, state, etc.
In the upper left corner there are sorting and filtering tools.
Sort by
You can sort the jobs by the following parameters:
- ID - ID Jobs
- Assignee - the user to whom the job is assigned
- Updated date - time and date of last saved job
- Stage - stage set on the task page
- State - state set by a user assigned to the job
- Task ID - the ID of the task to which the job belongs
- Project ID - the ID of the project containing the task to which the job belongs.
- Task name - the name of the task to which the job belongs
- Project name - the name of the project containing the task to which the job belongs.
To apply sorting, drag the parameter to the top area above the horizontal bar.
The parameters below the horizontal line will not be applied.
By moving the parameters you can change the priority,
first of all sorting will occur according to the parameters that are above.
Pressing the Sort button switches Ascending sort/Descending sort.
Quick filters
Quick Filters contain several frequently used filters:
Assigned to me - show only those jobs that are assigned to you.
Not completed - show only those jobs that have a status other than completed.
Filter
Applying filter disables the quick filter.
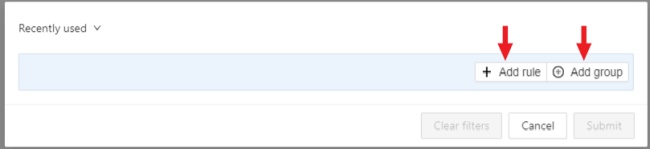
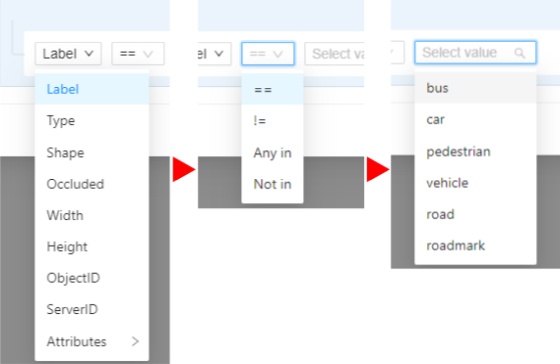
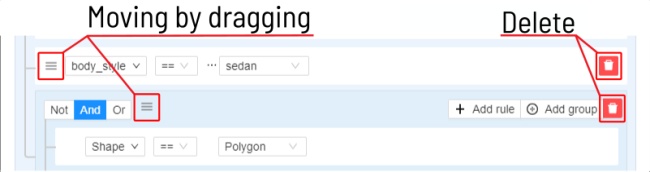
The filter works similarly to the filters for annotation,
you can create rules from properties,
operators
and values and group rules into groups.
For more details, see the filter section.
For clear all filters press Clear filters.
Supported properties for jobs list
Properties
Supported values
Description
State
all the state names
The state of the job (can be changed in the menu inside the job)
Stage
all the stage names
The stage of the job (is specified by a drop-down list on the task page)
Assignee is the user who is working on the job. (is specified on task page)
Last updated
last modified date and time (or value range)
The date can be entered in the dd.MM.yyyy HH:mm format or by selecting the date in the window that appears when you click on the input field
ID
number or range of job ID
Task ID
number or range of task ID
Project ID
number or range of project ID
Task name
task name
Set when creating a task, can be changed on the (task page)
Project name
project name
Specified when creating a project, can be changed on the (project section)
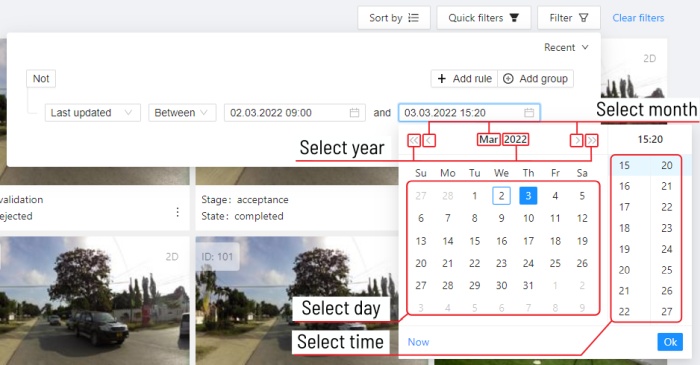
Date and time selection
When creating a Last updated rule, you can select the date and time by using the selection window.
You can select the year and month using the arrows or by clicking on the year and month,
to select a day, click on it in the calendar,
To select the time, you can select the hours and minutes using the scrolling list.
Or you can select the current date and time by clicking the Now button.
To apply, click Ok.
2.1.4 - Tasks page
Overview of the Tasks page.
The tasks page contains elements and each of them relates to a separate task. They are sorted in creation order.
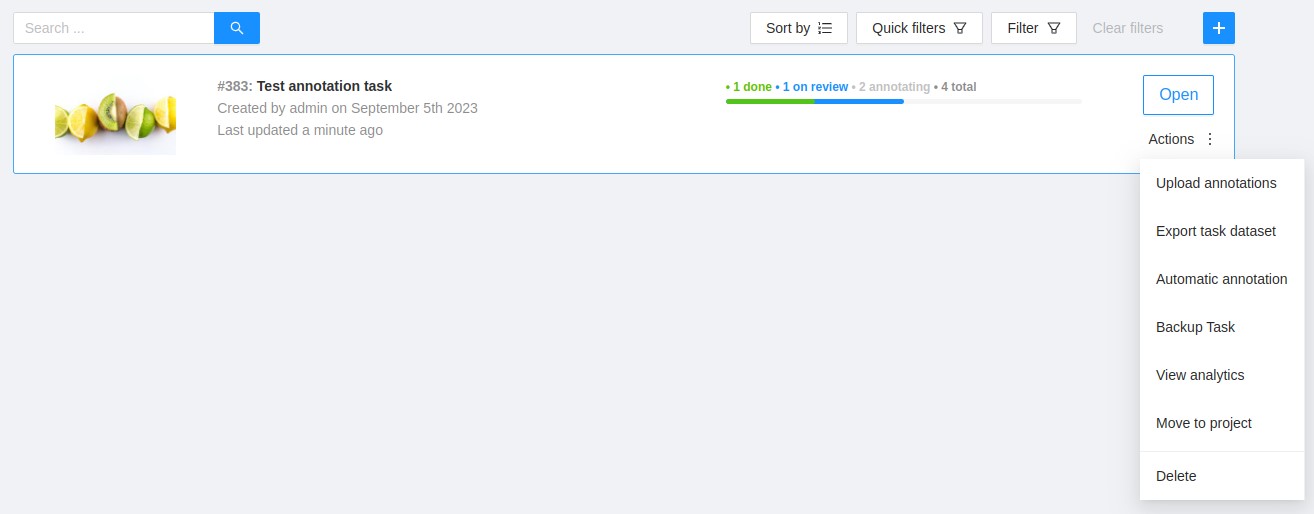
Each element contains: task name, preview, progress bar, button Open, and menu Actions.
Each button is responsible for a in menu Actions specific function:
Export task dataset — download annotations or annotations and images in a specific format.
More information is available in the export/import datasets
section.
Upload annotation upload annotations in a specific format.
More information is available in the export/import datasets
section.
Automatic Annotation — automatic annotation with OpenVINO toolkit.
Presence depends on how you build the CVAT instance.
Backup task — make a backup of this task into a zip archive.
Read more in the backup section.
Move to project — Moving a task to a project (can be used to move a task from one project to another).
Note that attributes reset during the moving process. In case of label mismatch,
you can create or delete necessary labels in the project/task.
Some task labels can be matched with the target project labels.
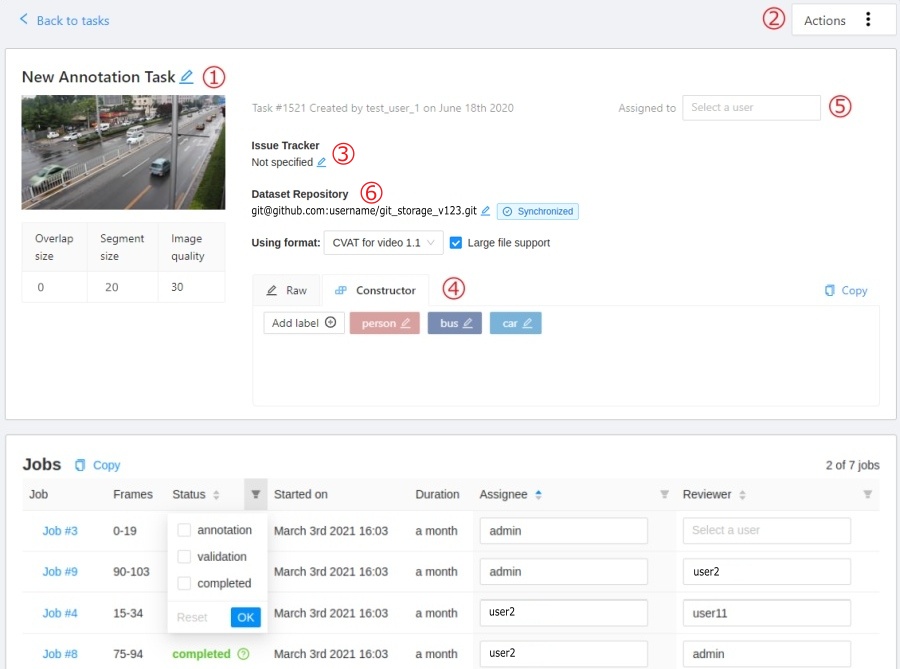
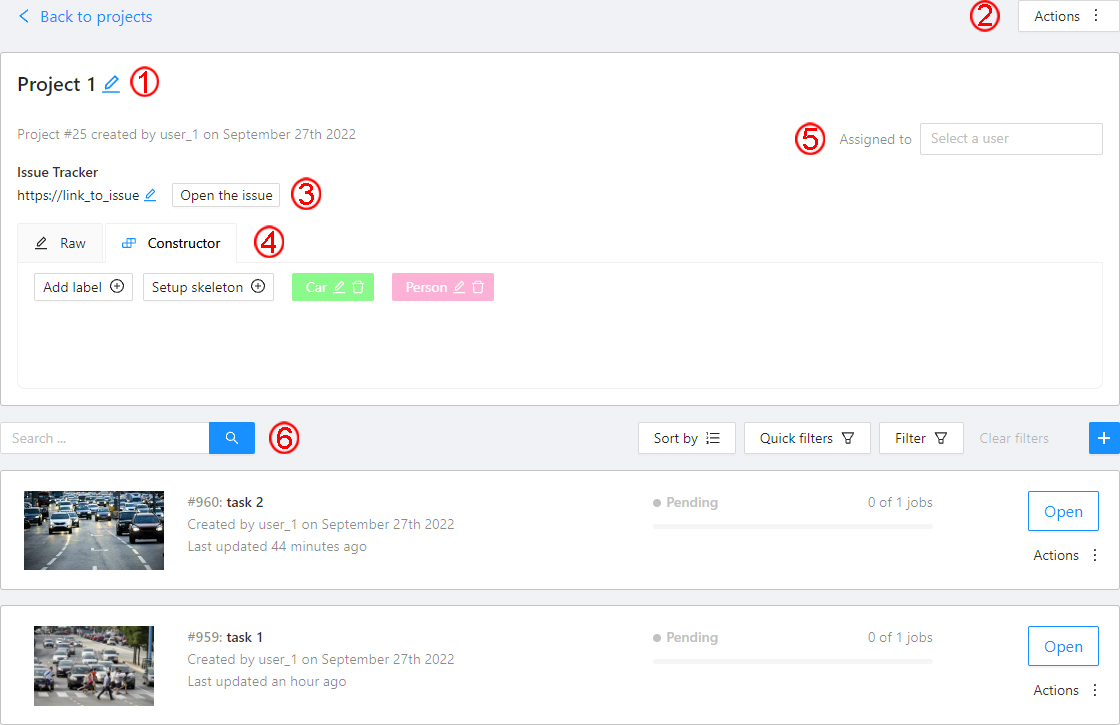
Task details is a task page which contains a preview, a progress bar
and the details of the task (specified when the task was created) and the jobs section.
The next actions are available on this page:
Change the task’s title.
Open Actions menu.
Change issue tracker or open issue tracker if it is specified.
Change labels (available only if the task is not related to the project).
You can add new labels or add attributes for the existing labels in the Raw mode or the Constructor mode.
By clicking Copy you will copy the labels to the clipboard.
Assigned to — is used to assign a task to a person. Start typing an assignee’s name and/or
choose the right person out of the dropdown list.
In the list of users, you will only see the users of the organization
where the task is created.
Dataset Repository
Repository link
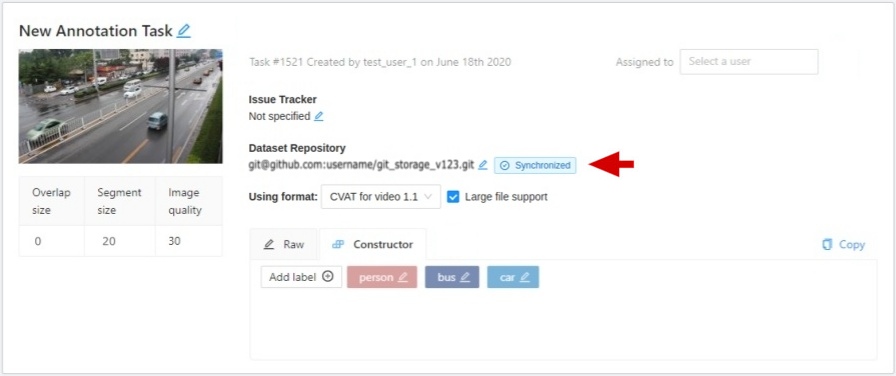
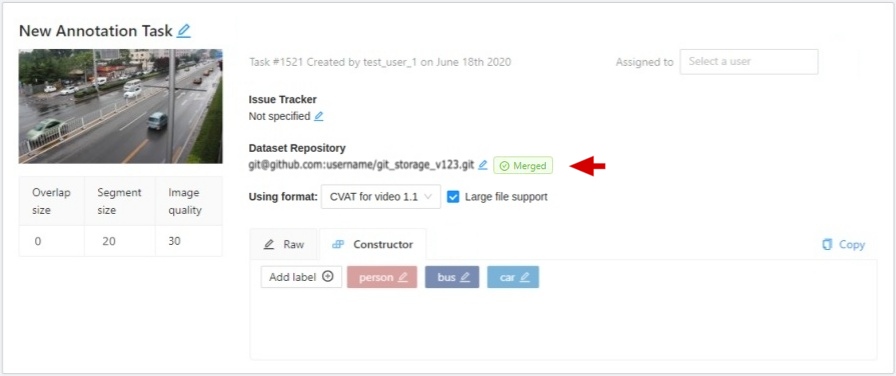
Synchronization status with dataset repository.
When you click on the status, the current annotation will be sent. It has several states:
Synchronized - task synchronized, that is, created a pull of requisites with an actual annotation file.
Merged - merged pull request with up-to-date annotation file.
Synchronize - highlighted in red, annotations are not synced.
Use a format drop-down list of formats in which the annotation can be synchronized.
Jobs — is a list of all jobs for a particular task. Here you can find the next data:
Jobs name with a hyperlink to it.
Frames — the frame interval.
A stage of the job. The stage is specified by a drop-down list.
There are three stages: annotation, validation or acceptance. This value affects the task progress bar.
A state of the job. The state can be changed by an assigned user in the menu inside the job.
There are several possible states: new, in progress, rejected, completed.
Started on — start date of this job.
Duration — is the amount of time the job is being worked.
Assignee is the user who is working on the job.
You can start typing an assignee’s name and/or choose the right person out of the dropdown list.
Reviewer – a user assigned to carry out the review,
read more in the review section.
Copy. By clicking Copy you will copy the job list to the clipboard.
The job list contains direct links to jobs.
You can filter or sort jobs by status, as well as by assigner or reviewer.
Follow a link inside Jobs section to start annotation process.
In some cases, you can have several links. It depends on size of your
task and Overlap Size and Segment Size parameters. To improve
UX, only the first chunk of several frames will be loaded and you will be able
to annotate first images. Other frames will be loaded in background.
2.1.6 - Interface of the annotation tool
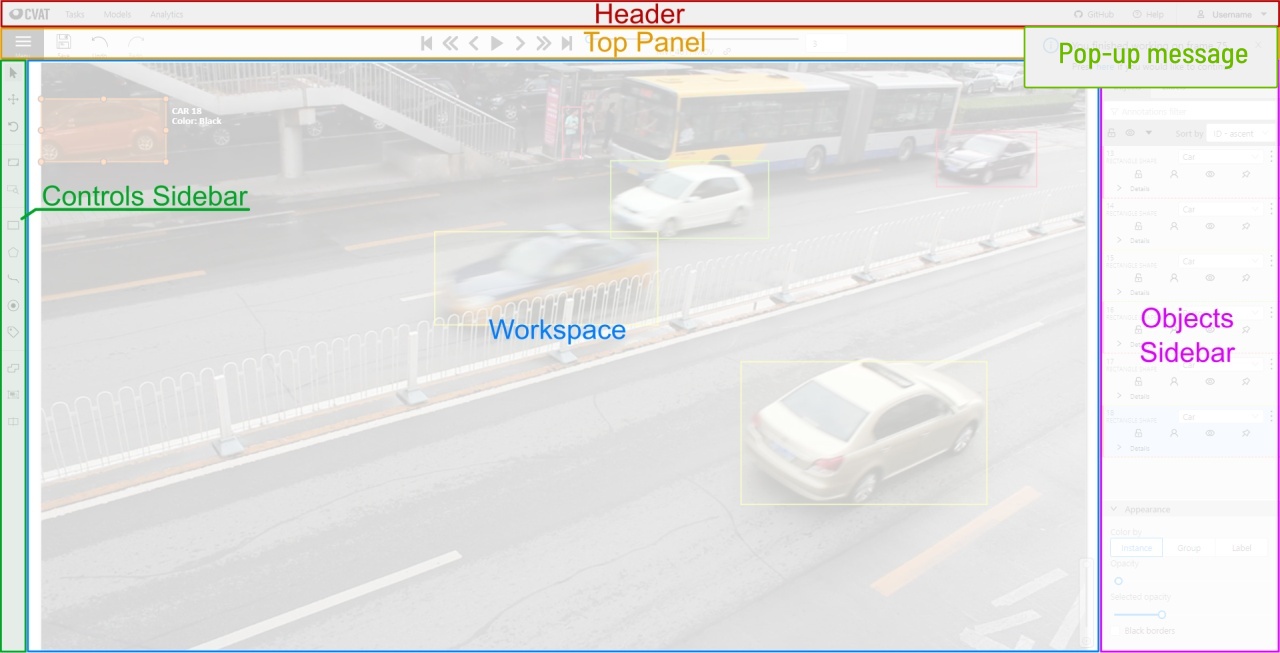
Main user interface
The tool consists of:
Header - pinned header used to navigate CVAT sections and account settings;
Top panel — contains navigation buttons, main functions and menu access;
Controls sidebar — contains tools for navigating the image, zoom,
creating shapes and editing tracks (merge, split, group);
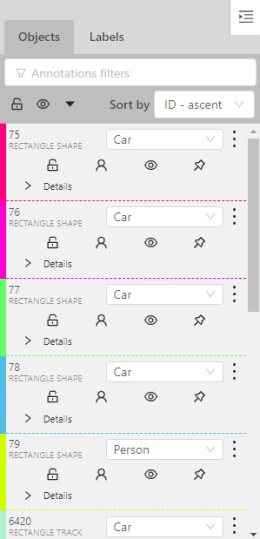
Objects sidebar — contains label filter, two lists:
objects (on the frame) and labels (of objects on the frame) and appearance settings.
Pop-up messages
In CVAT, you’ll receive pop-up messages in the upper-right corner, on any page.
Pop-up messages can contain useful information, links, or error messages.
Continue to the frame on which the work on the job is finished
When you open a job that you previously worked on, you will receive pop-up messages with a proposal
to go to the frame that was visited before closing the tab.
Error Messages
If you perform impossible actions, you may receive an error message.
The message may contain information about the error
or a prompt to open the browser console (shortcut F12) for information.
If you encounter a bug that you can’t solve yourself,
you can create an issue on GitHub.
2.1.7 - Basic navigation
Overview of basic controls.
Use arrows below to move to the next/previous frame.
Use the scroll bar slider to scroll through frames.
Almost every button has a shortcut.
To get a hint about a shortcut, just move your mouse pointer over an UI element.
To navigate the image, use the button on the controls sidebar.
Another way an image can be moved/shifted is by holding the left mouse button inside
an area without annotated objects.
If the Mouse Wheel is pressed, then all annotated objects are ignored. Otherwise the
a highlighted bounding box will be moved instead of the image itself.
You can use the button on the sidebar controls to zoom on a region of interest.
Use the button Fit the image to fit the image in the workspace.
You can also use the mouse wheel to scale the image
(the image will be zoomed relatively to your current cursor position).
2.1.8 - Top Panel
Overview of controls available on the top panel of the annotation tool.
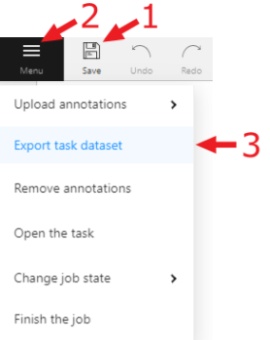
Menu button
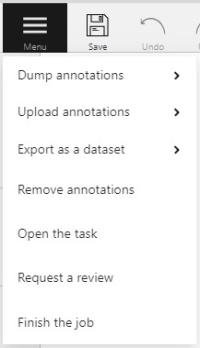
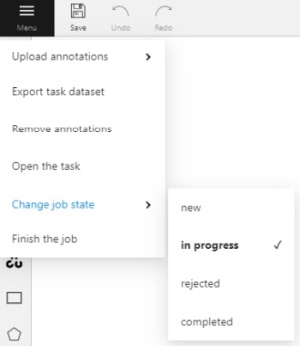
It is the main menu of the annotation tool. It can be used to download, upload and remove annotations.
Button assignment:
Upload Annotations — uploads annotations into a task.
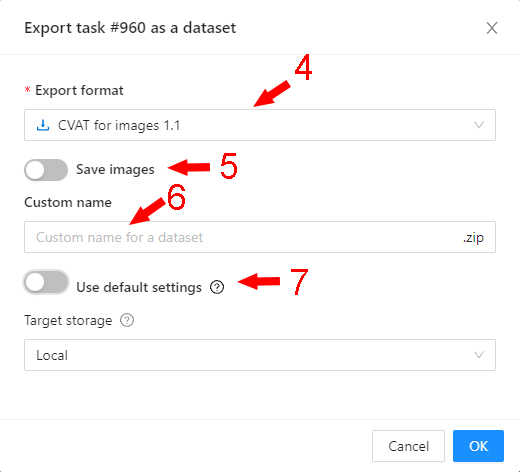
Export as a dataset — download a data set from a task in one of the supported formats.
You can also enter a Custom name and enable the Save images checkbox if you want the dataset to contain images.
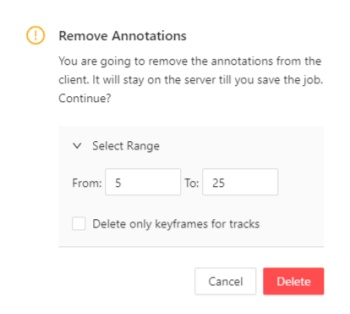
Remove Annotations — calls the confirmation window if you click Delete, the annotation of the current job
will be removed, if you click Select range you can remove annotation on range frames, if you activate checkbox
Delete only keyframe for tracks then only keyframes will be deleted from the tracks, on the selected range.
Open the task — opens a page with details about the task.
Change job state - changes the state of the job (new, in progress, rejected, completed).
Finish the job/Renew the job - changes the job stage and state
to acceptance and completed / annotation and new correspondingly.
Save Work
Saves annotations for the current job. The button has an indication of the saving process.
Undo-redo buttons
Use buttons to undo actions or redo them.
Done
Used to complete the creation of the object. This button appears only when the object is being created.
Block
Used to pause automatic line creation when drawing a polygon with
OpenCV Intelligent scissors.
Also used to postpone server requests when creating an object using AI Tools.
When blocking is activated, the button turns blue.
Player
Go to the first /the latest frames.
Go to the next/previous frame with a predefined step. Shortcuts:
V — step backward, C — step forward. By default the step is 10 frames
(change at Account Menu —> Settings —> Player Step).
The button to go to the next / previous frame has the customization possibility.
To customize, right-click on the button and select one of three options:
The default option - go to the next / previous frame (the step is 1 frame).
Go to the next / previous frame that has any objects (in particular filtered).
Read the filter section to know the details how to use it.
Go to the next / previous frame without annotation at all.
Use this option in cases when you need to find missed frames quickly.
Shortcuts: D - previous, F - next.
Play the sequence of frames or the set of images.
Shortcut: Space (change at Account Menu —> Settings —> Player Speed).
Go to a specific frame. Press ~ to focus on the element.
Fullscreen Player
The fullscreen player mode. The keyboard shortcut is F11.
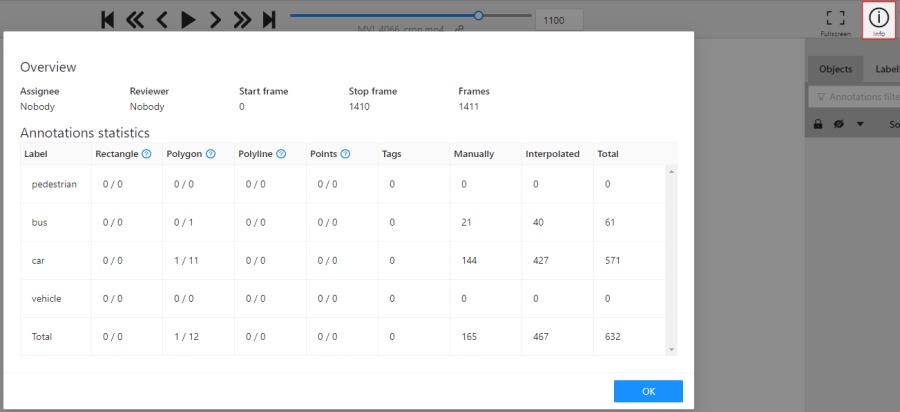
Info
Open the job info.
Overview:
Assignee - the one to whom the job is assigned.
Reviewer – a user assigned to carry out the review,
read more in the review section.
Start Frame - the number of the first frame in this job.
End Frame - the number of the last frame in this job.
Frames - the total number of all frames in the job.
Annotations statistics:
This is a table number of created shapes, sorted by labels (e.g. vehicle, person)
and type of annotation (shape, track). As well as the number of manual and interpolated frames.
UI switcher
Switching between user interface modes.
2.1.9 - Controls sidebar
Overview of available functions on the controls sidebar of the annotation tool.
Navigation
Navigation block - contains tools for moving and rotating images.
Icon
Description
Cursor (Esc)- a basic annotation pedacting tool.
Move the image- a tool for moving around the image without the possibility of editing.
Rotate- two buttons to rotate the current frame a clockwise (Ctrl+R) and anticlockwise (Ctrl+Shift+R). You can enable Rotate all images in the settings to rotate all the images in the job
Zoom
Zoom block - contains tools for image zoom.
Icon
Description
Fit image- fits image into the workspace size. Shortcut - double click on an image
Select a region of interest- zooms in on a selected region. You can use this tool to quickly zoom in on a specific part of the frame.
Shapes
Shapes block - contains all the tools for creating shapes.
Overview of available functions on the objects sidebar of the annotation tool.
Hide objects sidebar
Hide - the button hides the object’s sidebar.
Objects
Filter input box
The way how to use filters is described in the advanced guide here.
List of objects
Switch lock property for all - switches lock property of all objects in the frame.
Switch hidden property for all - switches hide property of all objects in the frame.
Expand/collapse all - collapses/expands the details field of all objects in the frame.
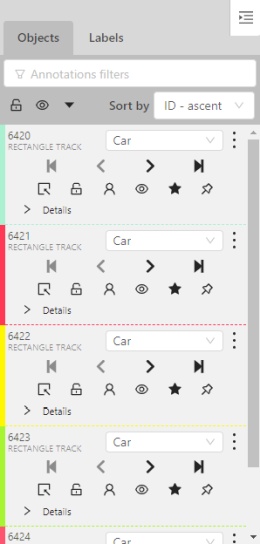
Sorting - sort the list of objects: updated time, ID - accent, ID - descent
In the objects sidebar you can see the list of available objects on the current
frame. The following figure is an example of how the list might look like:
Shape mode
Track mode
Objects on the side bar
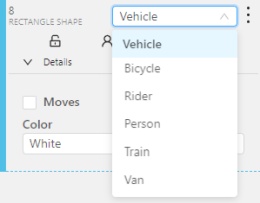
The type of a shape can be changed by selecting Label property.
For instance, it can look like shown on the figure below:
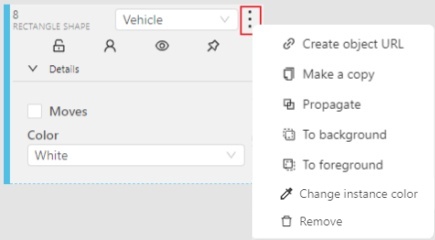
Object action menu
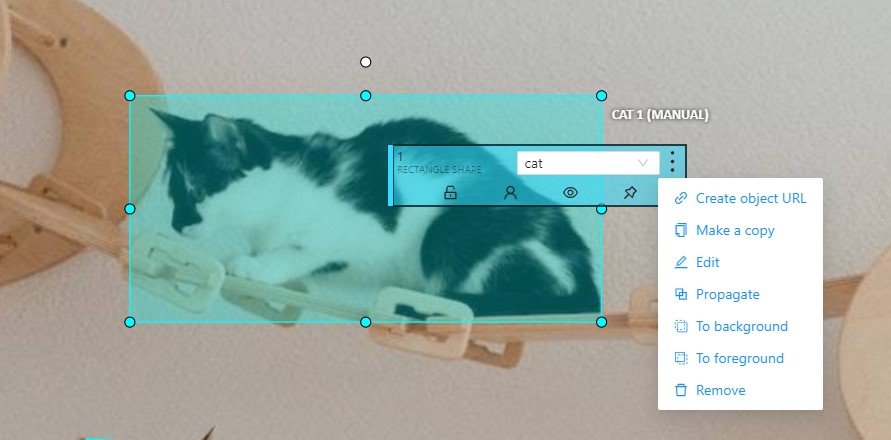
The action menu calls up the button:
The action menu contains:
Create object URL - puts a link to an object on the clipboard.
After you open the link, this object will be filtered.
Make a copy- copies an object. The keyboard shortcut is Ctrl + CCtrl + V.
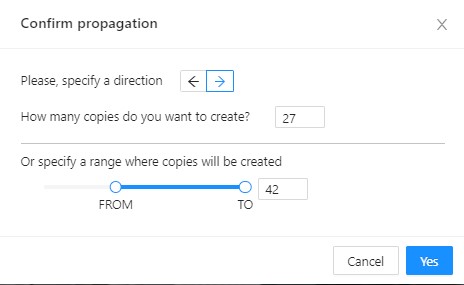
Propagate - Сopies the form to several frames,
invokes a dialog box in which you can specify the number of copies
or the frame onto which you want to copy the object. The keyboard shortcut Ctrl + B.
To background - moves the object to the background. The keyboard shortcut -,_.
To foreground - moves the object to the foreground. The keyboard shortcut +,=.
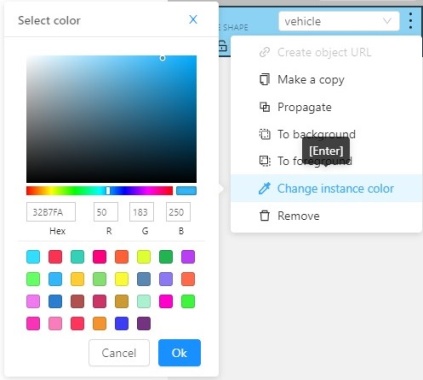
Change instance color- choosing a color using the color picker (available only in instance mode).
Remove - removes the object. The keyboard shortcut Del,Shift+Del.
A shape can be locked to prevent its modification or moving by an accident. Shortcut to lock an object: L.
A shape can be Occluded. Shortcut: Q. Such shapes have dashed boundaries.
You can change the way an object is displayed on a frame (show or hide).
Switch pinned property - when enabled, a shape cannot be moved by dragging or dropping.
Tracker switcher - enable/disable tracking for the object.
By clicking on the Details button you can collapse or expand the field with all the attributes of the object.
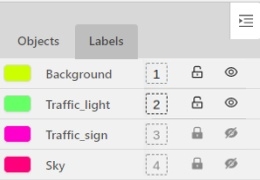
Labels
In this tab you can lock or hide objects of a certain label.
To change the color for a specific label,
you need to go to the task page and select the color by clicking the edit button,
this way you will change the label color for all jobs in the task.
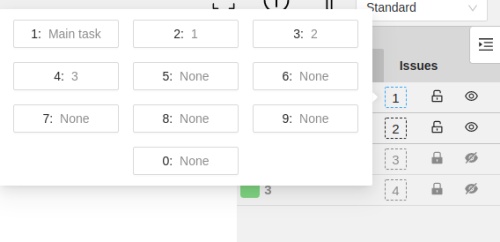
Fast label change
You can change the label of an object using hot keys.
In order to do it, you need to assign a number (from 0 to 9) to labels.
By default numbers 1,2…0 are assigned to the first ten labels.
To assign a number, click on the button placed at the right of a label name on the sidebar.
After that you will be able to assign a corresponding label to an object
by hovering your mouse cursor over it and pressing Ctrl + Num(0..9).
In case you do not point the cursor to the object, pressing Ctrl + Num(0..9) will set a chosen label as default,
so that the next object you create (use N key) will automatically have this label assigned.
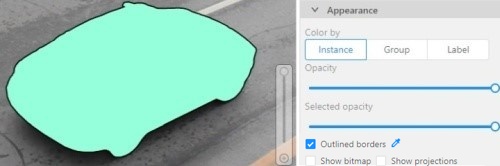
Appearance
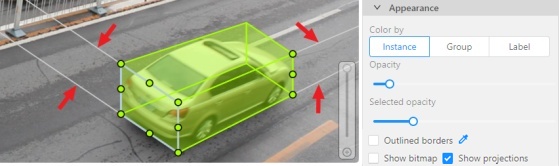
Color By options
Change the color scheme of annotation:
Instance — every shape has random color
Group — every group of shape has its own random color, ungrouped shapes are white
Label — every label (e.g. car, person) has its own random color
You can change any random color pointing to a needed box on a frame or on an
object sidebar.
Fill Opacity slider
Change the opacity of every shape in the annotation.
Selected Fill Opacity slider
Change the opacity of the selected object’s fill. It is possible to change opacity while drawing an object in the case
of rectangles, polygons and cuboids.
Outlines borders checkbox
You can change a special shape border color by clicking on the Eyedropper icon.
Show bitmap checkbox
If enabled all shapes are displayed in white and the background is black.
Show projections checkbox
Enables / disables the display of auxiliary perspective lines. Only relevant for cuboids
2.1.11 - Workspace
Overview of available functions on the workspace of the annotation tool.
This is the main field in which drawing and editing objects takes place.
In addition the workspace also has the following functions:
Right-clicking on an object calls up the Object card - this is an element containing
the necessary controls for changing the label and attributes of the object, as well as the action menu.
Right-clicking a point deletes it.
Z-axis slider - Allows you to switch annotation layers hiding the upper layers
(slider is enabled if several z layers are on a frame).
This element has a button for adding a new layer. When pressed, a new layer is added and switched to it.
You can move objects in layers using the + and - keys.
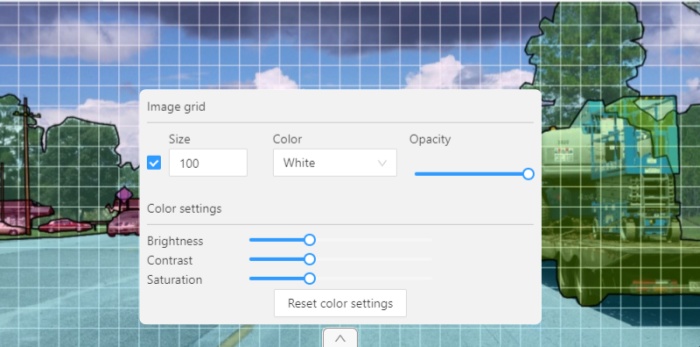
Image settings panel - used to set up the grid and set up image brightness contrast saturation.
Show Grid, change grid size, choose color and transparency:
Adjust Brightness/Contrast/Saturation of too exposed or too
dark images using F3 — color settings (changes displaying settings and not the
image itself).
Shortcuts:
Shift+B+=/Shift+B+- for brightness.
Shift+C+=/Shift+C+- for contrast.
Shift+S+=/Shift+S+- for saturation.
Reset color settings to default values.
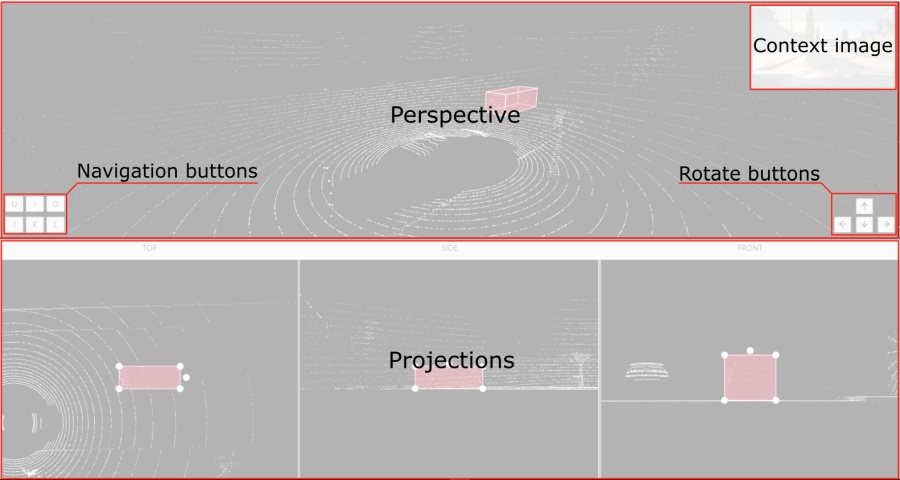
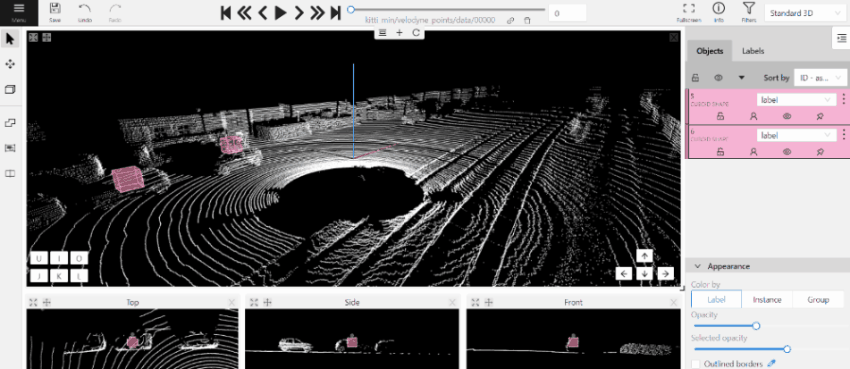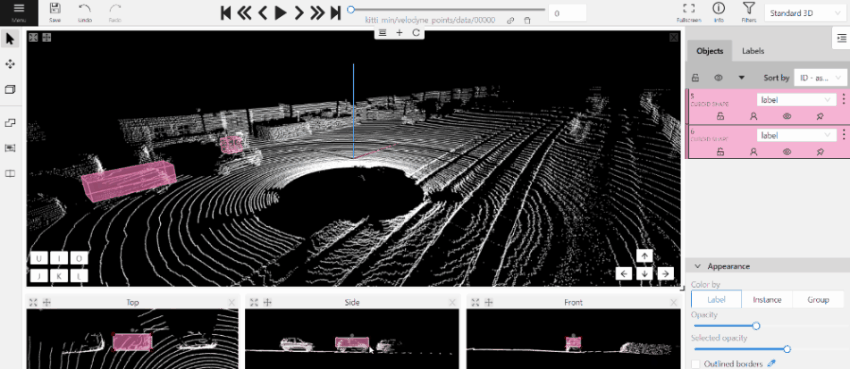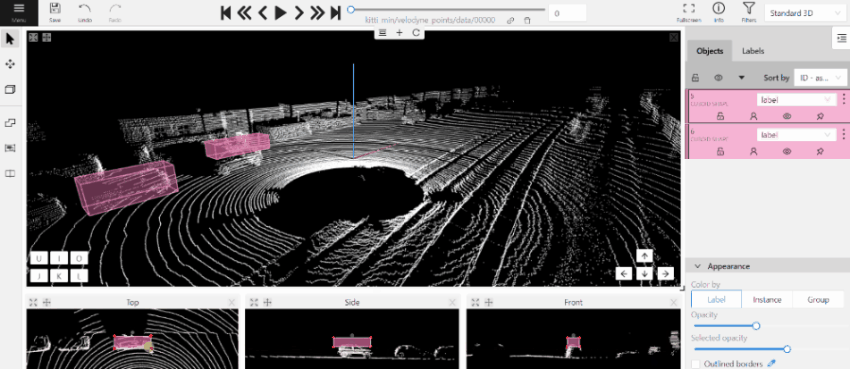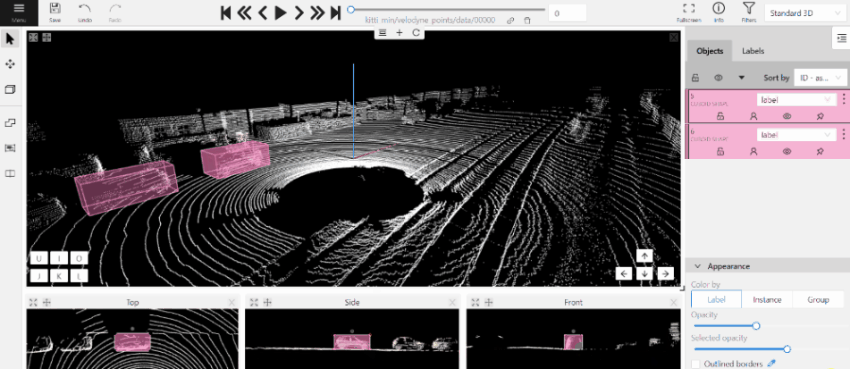
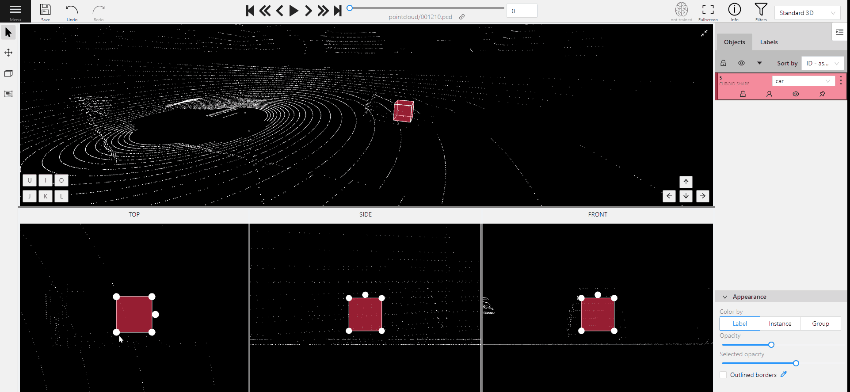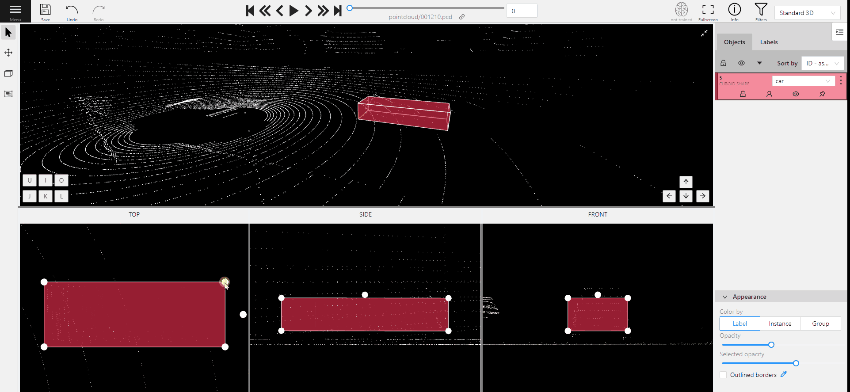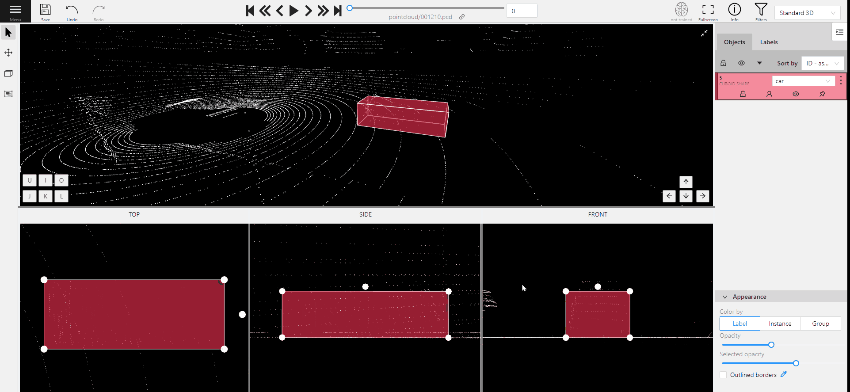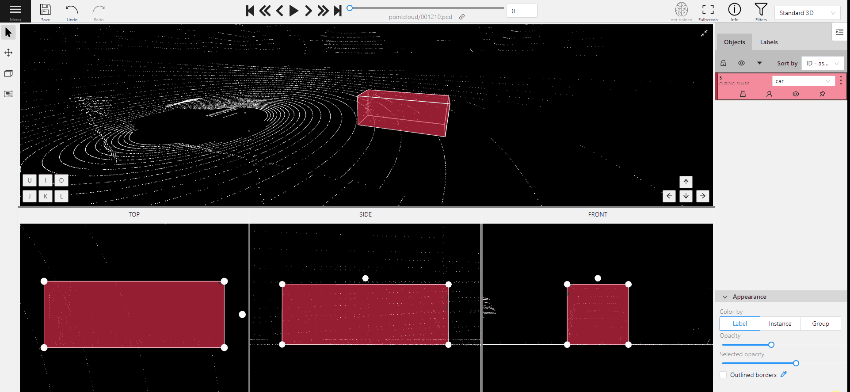
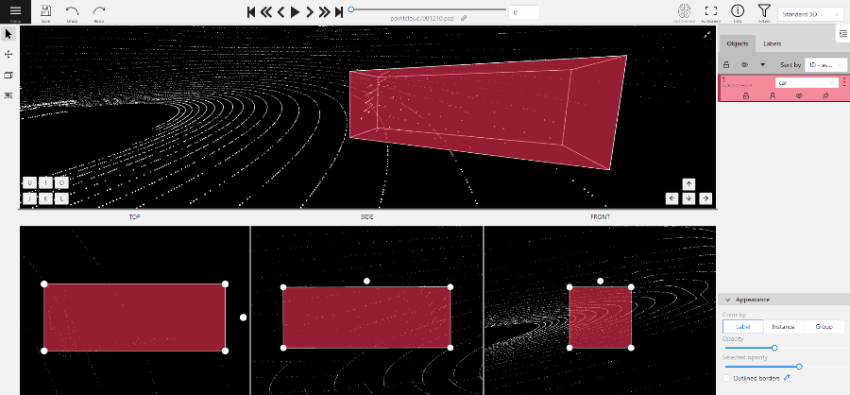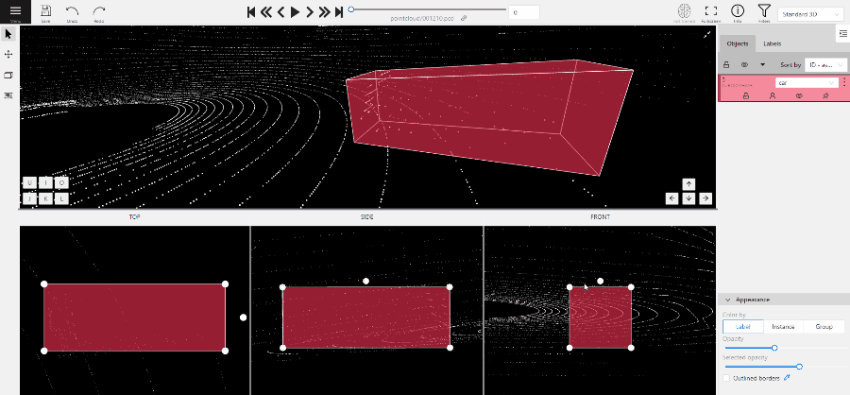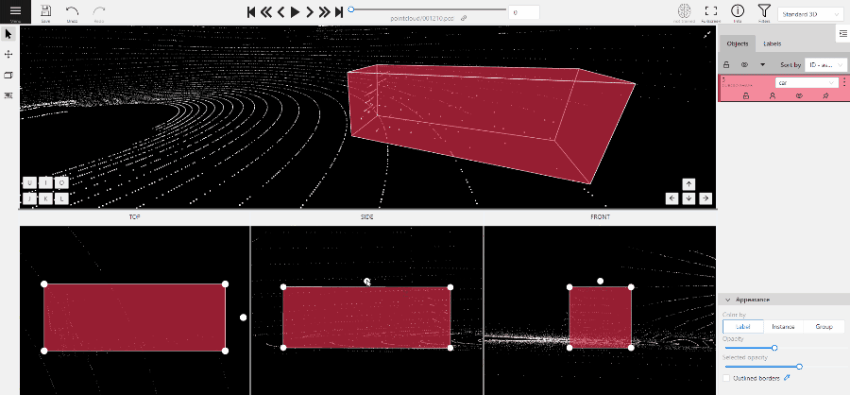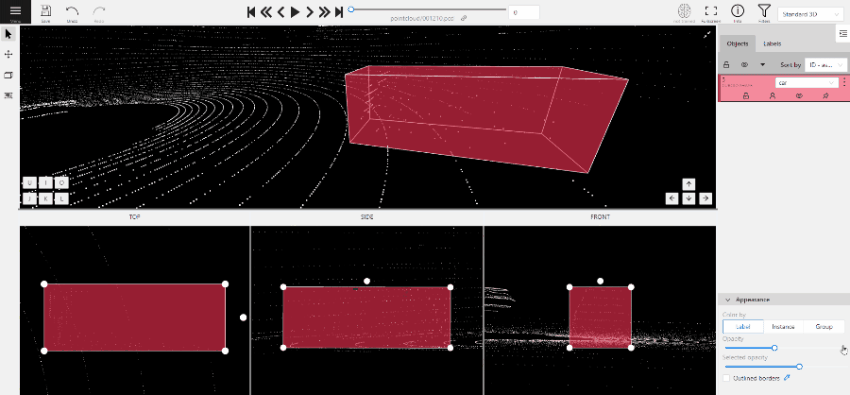
2.1.12 - 3D task workspace
If the related_images folder contains any images, a context image will be available in the perspective window.
The contextual image could be compared to 3D data and would help to identify the labels of marked objects.
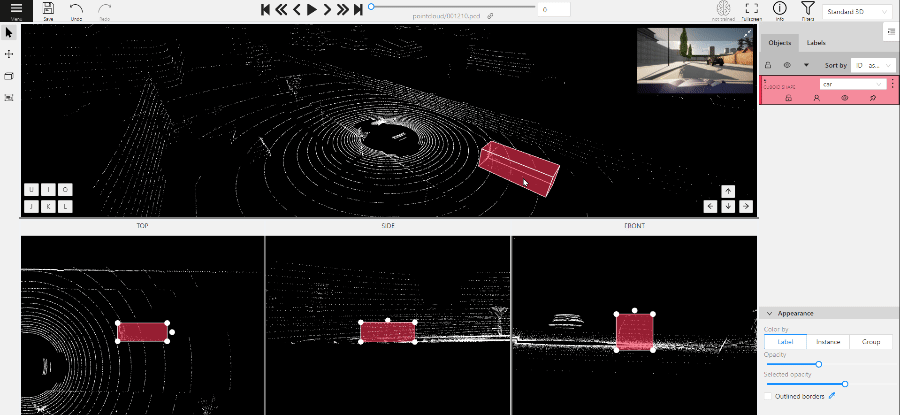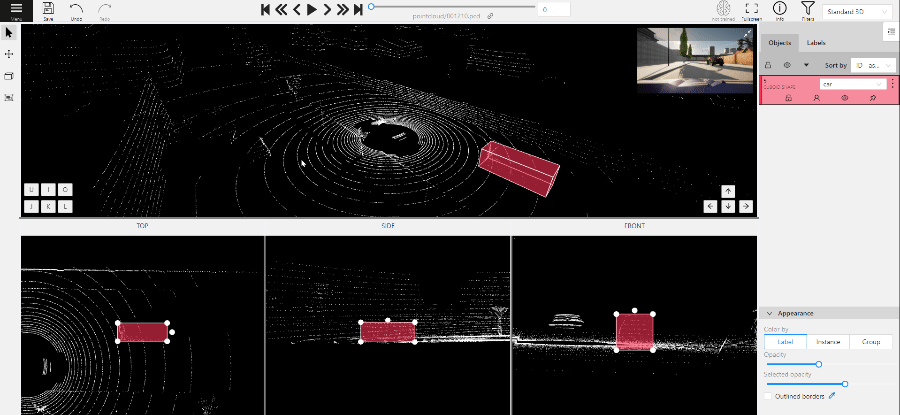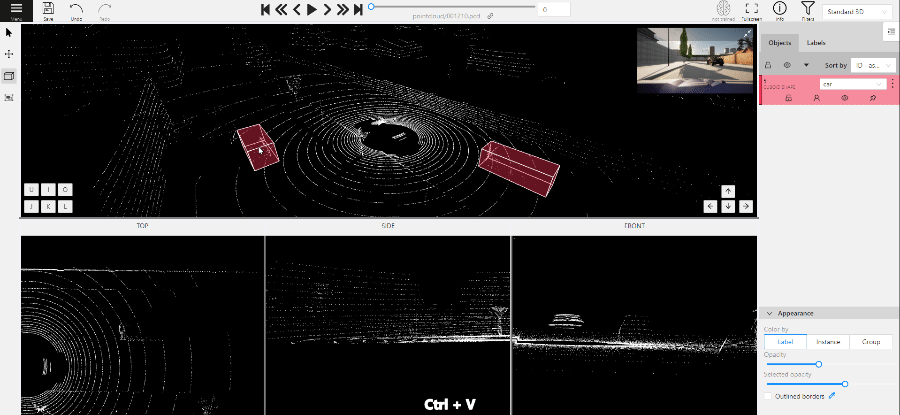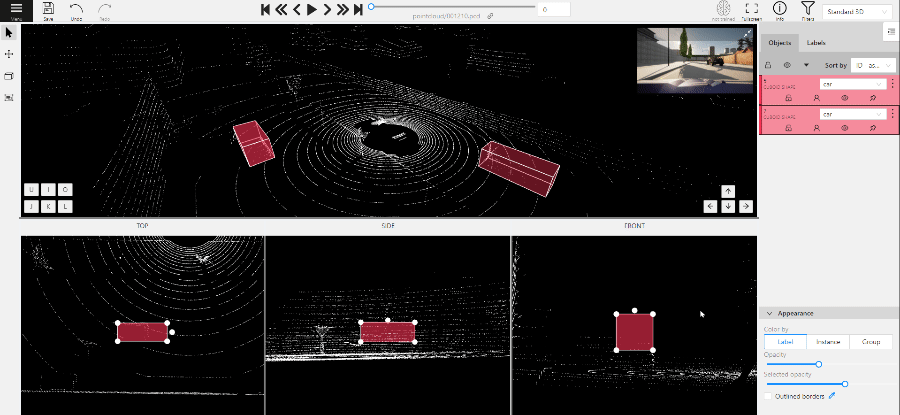
Perspective – a main window for work with objects in a 3D task.
Projections - projections are tied to an object so that a cuboid is in the center and looks like a rectangle.
Projections show only the selected object.
Top – a projection of the view from above.
Side – a projection of the left side of the object.
Front - a frontal projection of the object.
2.1.13 - Standard 3D mode (basics)
Standard 3d mode - Designed to work with 3D data.
The mode is automatically available if you add PCD or Kitty BIN format data when you create a task.
read more
You can adjust the size of the projections, to do so, simply drag the boundary between the projections.
2.1.14 - Settings
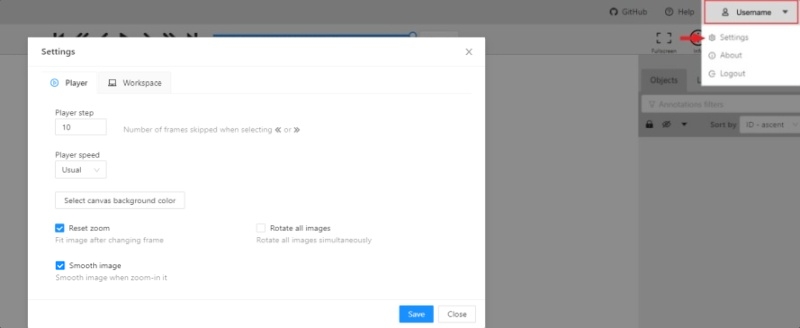
To open the settings open the user menu in the header and select the settings item or press F2.
Settings have two tabs:
In tab Player you can:
Control step of C and V shortcuts.
Control speed of Space/Play button.
Select canvas background color. You can choose a background color or enter manually (in RGB or HEX format).
Reset zoom Show every image in full size or zoomed out like previous
(it is enabled by default for interpolation mode and disabled for annotation mode).
Rotate all images checkbox — switch the rotation of all frames or an individual frame.
Smooth image checkbox — smooth image when zoom-in it.
smoothed
pixelized
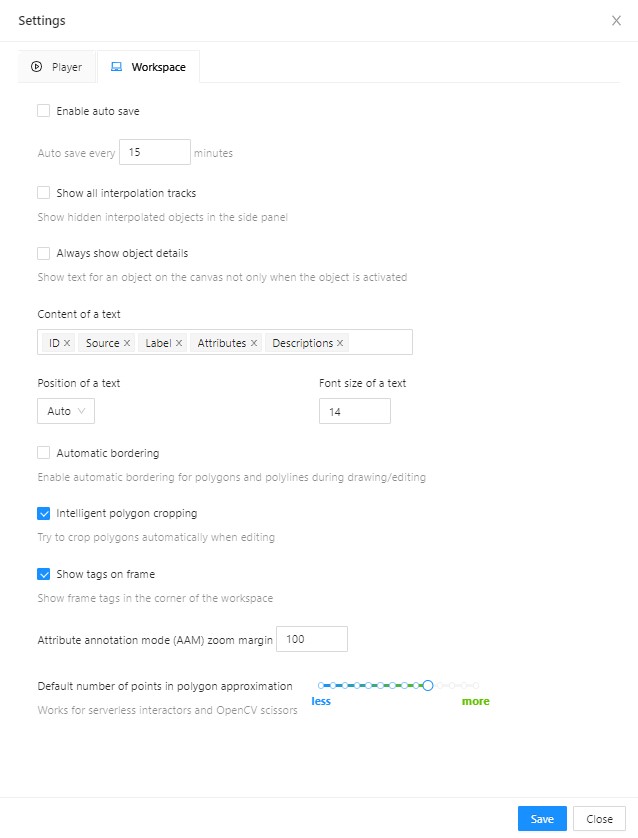
In tab Workspace you can:
Enable auto save checkbox — turned off by default.
Auto save interval (min) input box — 15 minutes by default.
Show all interpolation tracks checkbox — shows hidden objects on the
side panel for every interpolated object (turned off by default).
Always show object details - show text for an object on the canvas not only when the object is activated:
Content of a text - setup of the composition of the object details:
ID - object identifier.
Attributes - attributes of the object.
Label - object label.
Source- source of creating of objects MANUAL, AUTO or SEMI-AUTO.
Descriptions - description of attributes.
Position of a text - text positioning mode selection:
Auto - the object details will be automatically placed where free space is.
Center - the object details will be embedded to a corresponding object if possible.
Font size of a text - specifies the text size of the object details.
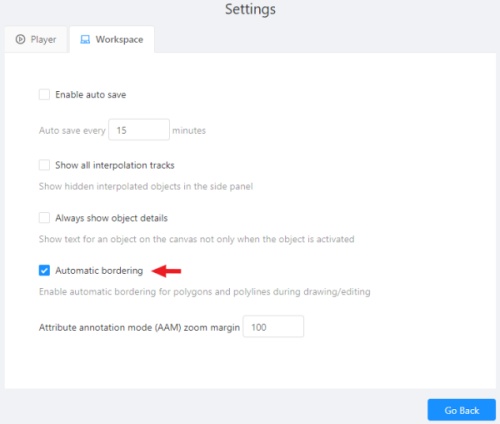
Automatic bordering - enable automatic bordering for polygons and polylines during drawing/editing.
For more information To find out more, go to the section annotation with polygons.
Intelligent polygon cropping - activates intelligent cropping when editing the polygon (read more in the section edit polygon
Attribute annotation mode (AAM) zoom margin input box — defines margins (in px)
for shape in the attribute annotation mode.
Click Save to save settings (settings will be saved on the server and will not change after the page is refreshed).
Click Cancel or press F2 to return to the annotation.
Default number of points in polygon approximation
With this setting, you can choose the default number of points in polygon.
Works for serverless interactors and OpenCV scissors.
2.1.15 - Types of shapes
List of shapes available for annotation.
There are several shapes with which you can annotate your images:
Rectangle or Bounding box
Polygon
Polyline
Points
Ellipse
Cuboid
Cuboid in 3d task
Tag
And there is how they all look like:
Tag - has no shape in the workspace, but is displayed in objects sidebar.
2.1.16 - Shape mode (basics)
Usage examples and basic operations available during annotation in shape mode.
Usage examples:
Create new annotations for a set of images.
Add/modify/delete objects for existing annotations.
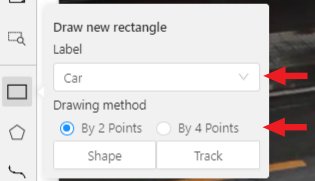
You need to select Rectangle on the controls sidebar:
Before you start, select the correct Label (should be specified by you when creating the task)
and Drawing Method (by 2 points or by 4 points):
Creating a new annotation in Shape mode:
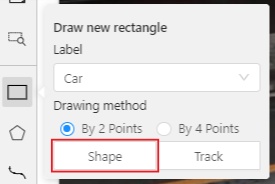
Create a separate Rectangle by clicking on Shape.
Choose the opposite points. Your first rectangle is ready!
To learn more about creating a rectangle read here.
It is possible to adjust boundaries and location of the rectangle using a mouse.
Rectangle’s size is shown in the top right corner , you can check it by clicking on any point of the shape.
You can also undo your actions using Ctrl+Z and redo them with Shift+Ctrl+Z or Ctrl+Y.
You can see the Object card in the objects sidebar or open it by right-clicking on the object.
You can change the attributes in the details section.
You can perform basic operations or delete an object by clicking on the action menu button.
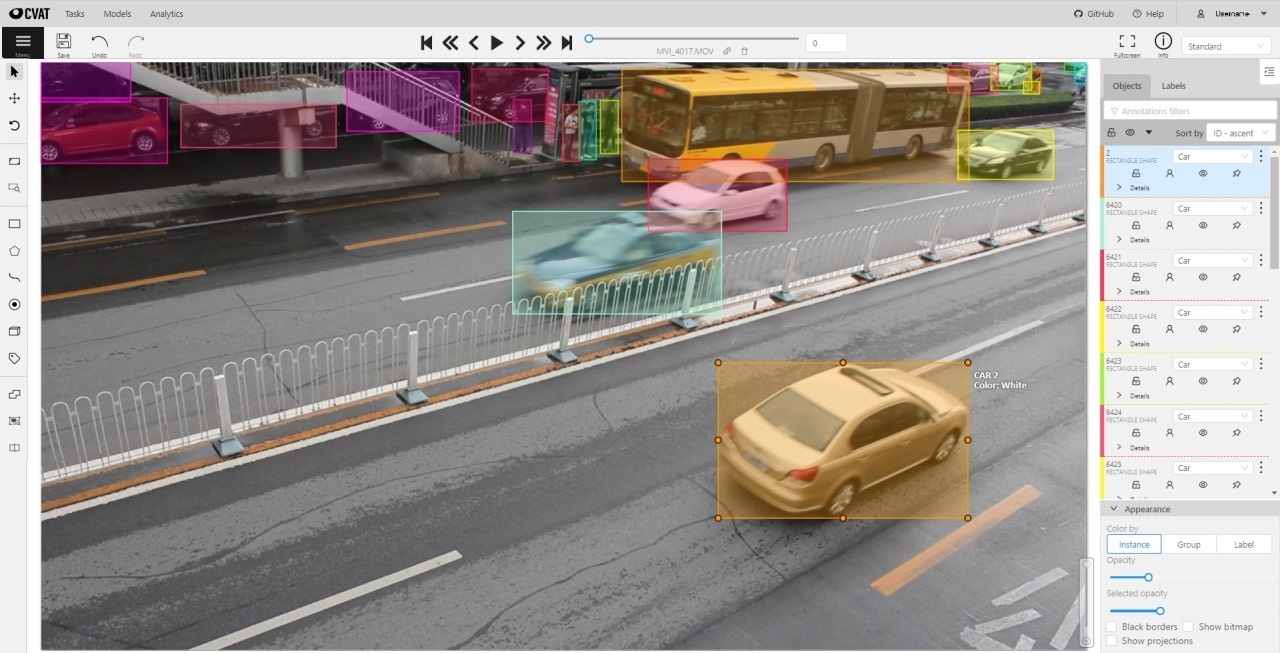
The following figure is an example of a fully annotated frame with separate shapes.
Usage examples and basic operations available during annotation in track mode.
Usage examples:
Create new annotations for a sequence of frames.
Add/modify/delete objects for existing annotations.
Edit tracks, merge several rectangles into one track.
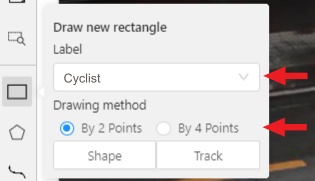
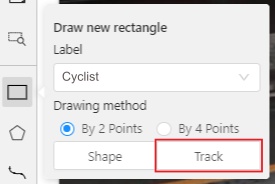
Like in the Shape mode, you need to select a Rectangle on the sidebar,
in the appearing form, select the desired Label and the Drawing method.
Creating a track for an object (look at the selected car as an example):
Create a Rectangle in Track mode by clicking on Track.
In Track mode the rectangle will be automatically interpolated on the next frames.
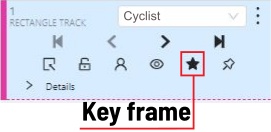
The cyclist starts moving on frame #2270. Let’s mark the frame as a key frame.
You can press K for that or click the star button (see the screenshot below).
If the object starts to change its position, you need to modify the rectangle where it happens.
It isn’t necessary to change the rectangle on each frame, simply update several keyframes
and the frames between them will be interpolated automatically.
Let’s jump 30 frames forward and adjust the boundaries of the object. See an example below:
After that the rectangle of the object will be changed automatically on frames 2270 to 2300:
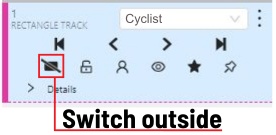
When the annotated object disappears or becomes too small, you need to
finish the track. You have to choose Outside Property, shortcut O.
If the object isn’t visible on a couple of frames and then appears again,
you can use the Merge feature to merge several individual tracks
into one.
Create tracks for moments when the cyclist is visible:
Click Merge button or press key M and click on any rectangle of the first track
and on any rectangle of the second track and so on:
Click Merge button or press M to apply changes.
The final annotated sequence of frames in Interpolation mode can
look like the clip below:
Overview of basic operations available when annotating 3D objects.
Navigation
To move in 3D space you can use several methods:
Select the move the image tool so you can move the camera using the mouse:
Hold down the left mouse button in the perspective window to turn the camera around the conditional point.
Hold down the right mouse button in the perspective window to move the camera inside the 3D space.
Move the mouse while holding down the wheel to zoom in/out in the perspective window.
Scroll the wheel to zoom in/out (works both in perspective and in projections).
Move using the keys in the perspective window
You can move around by pressing the corresponding buttons:
To rotate the camera use: Shift+arrrowup/Shift+arrrowdown/Shift+arrrowleft/Shift+arrrowright.
To move left/right use: Allt+J/Alt+L.
To move up/down use: Alt-U/Alt+O.
To zoom in/out use: Alt+K/Alt+I.
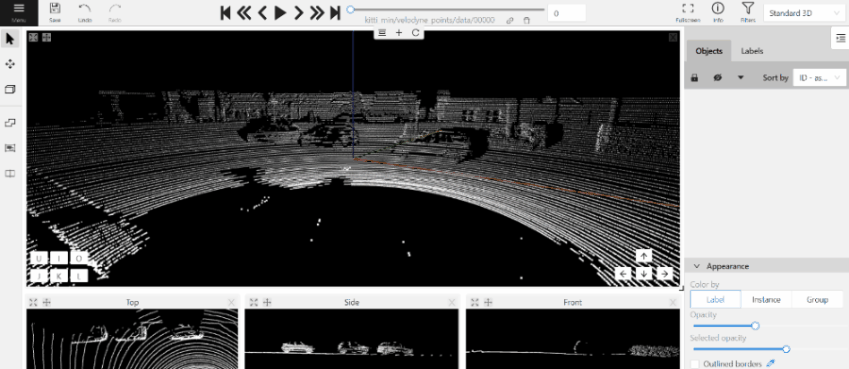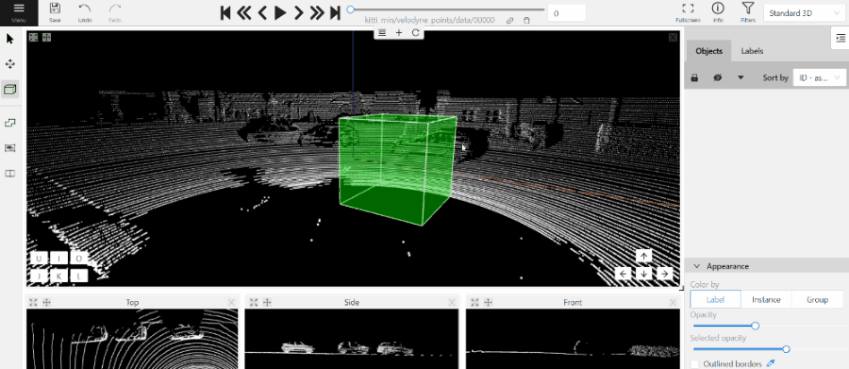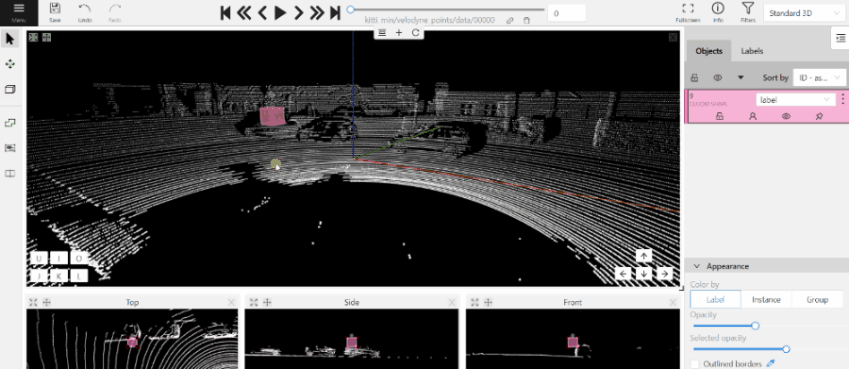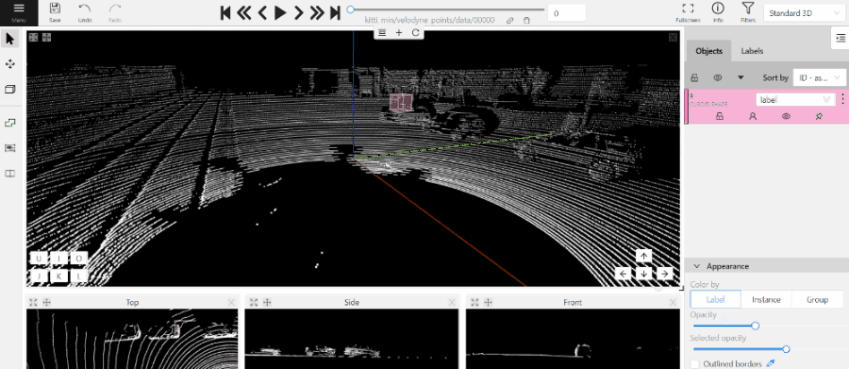
Creating a cuboid
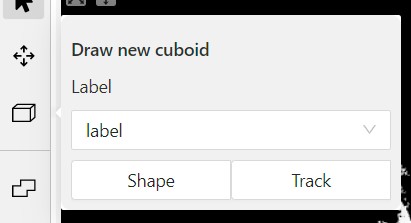
To create a cube in a 3D task you need to click the appropriate icon on the control sidebar,
select the label of the future object and click shape.
After that the cursor will be followed by a cube. In the creation process you can rotate and move the camera
only using the keys. Left double-click will create an object.
You can place an object only near the dots of the point cloud.
To adjust the size precisely, you need to edit the cuboid on the projections, for this change Сursor on control
sidebar or press Esc. In each projection you can:
Move the object in the projection plane - to do this, hover over the object,
press the left mouse button and move the object.
Move one of the four points - you can change the size of the cuboid by dragging the points in the projection.
Rotate the cuboid in the projection plane – to rotate the cuboid you should click on the appropriate point
and then drag it up/down or to the left/right.
2.1.19 - Attribute annotation mode (basics)
Usage examples and basic operations available in attribute annotation mode.
In this mode you can edit attributes with fast navigation between objects and frames using a keyboard.
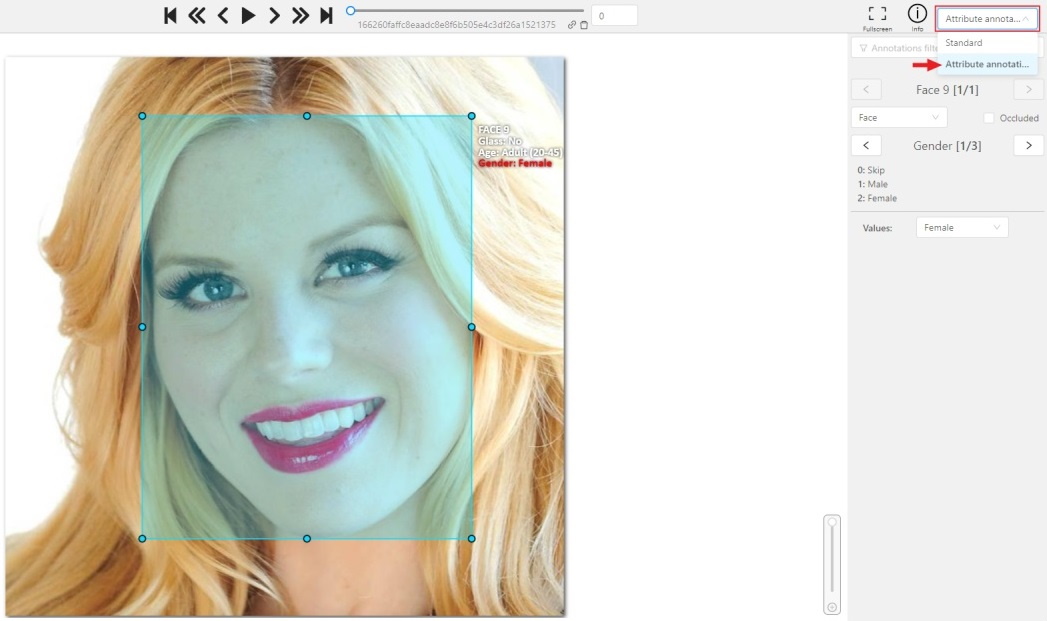
Open the drop-down list in the top panel and select Attribute annotation Mode.
In this mode objects panel change to a special panel :
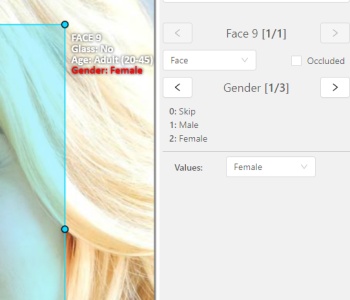
The active attribute will be red. In this case it is gender . Look at the bottom side panel to see all possible
shortcuts for changing the attribute. Press key 2 on your keyboard to assign a value (female) for the attribute
or select from the drop-down list.
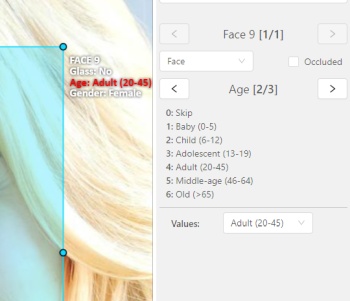
Press Up Arrow/Down Arrow on your keyboard or click the buttons in the UI to go to the next/previous
attribute. In this case, after pressing Down Arrow you will be able to edit the Age attribute.
Use Right Arrow/Left Arrow keys to move to the previous/next image with annotation.
Label is a type of an annotated object (e.g. person, car, vehicle, etc.)
Attribute is a property of an annotated object (e.g. color, model,
quality, etc.). There are two types of attributes:
Unique: immutable and can’t be changed from frame to frame (e.g. age, gender, color, etc.)
Temporary: mutable and can be changed on any frame (e.g. quality, pose, truncated, etc.)
Track is a set of shapes on different frames which corresponds to one object.
Tracks are created in Track mode
Annotation is a set of shapes and tracks. There are several types of annotations:
Manual which is created by a person
Semi-automatic which is created mainly automatically, but the user provides some data (e.g. interpolation)
Automatic which is created automatically without a person in the loop
Approximation allows you to reduce the number of points in the polygon.
Can be used to reduce the annotation file and to facilitate editing polygons.
Trackable object will be tracked automatically if the previous frame was
a latest keyframe for the object. More details in the section trackers.
State of the job. The state can be changed by an assigned user in the menu inside the job.
There are several possible states: new, in progress, rejected, completed.
Stage of the job. The stage is specified with the drop-down list on the task page.
There are three stages: annotation, validation or acceptance. This value affects the task progress bar.
2.1.21 - Cloud storages page
Overview of the cloud storages page.
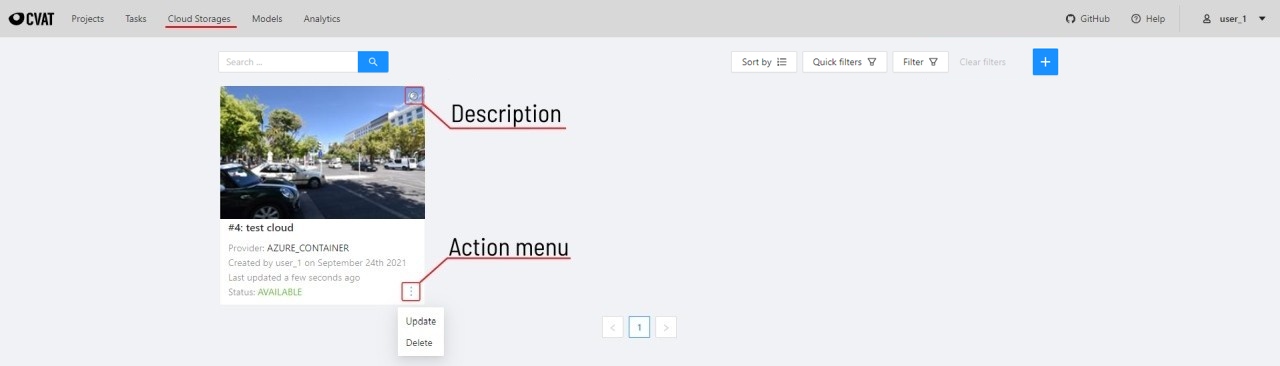
The cloud storages page contains elements, each of them relating to a separate cloud storage.
Each element contains: preview, cloud storage name, provider, creation and update info, status,
? button for displaying the description and the actions menu.
Each button in the action menu is responsible for a specific function:
Update — update this cloud storage
Delete — delete cloud storage.
This preview will appear when it is impossible to get a real preview (e.g. storage is empty or
invalid credentials were used).
Instructions on how to attach cloud storage using UI
In CVAT you can use AWS-S3 and Azure Blob Container cloud storages to store image datasets for your tasks.
Using AWS-S3
Create AWS account
First, you need to create an AWS account, to do this, register of 5 steps
following the instructions
(even if you plan to use a free basic account you may need to link a credit card to verify your identity).
To learn more about the operation and benefits of AWS cloud,
take a free AWS Cloud Practitioner Essentials course,
which will be available after registration.
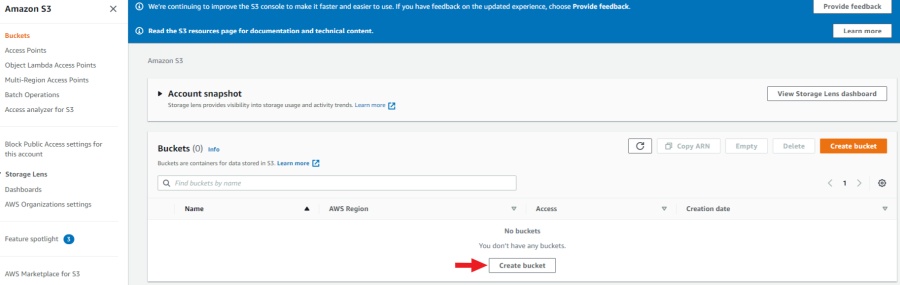
Create a bucket
After the account is created, go to console AWS-S3
and click Create bucket.
You’ll be taken to the bucket creation page. Here you have to specify the name of the bucket, region,
optionally you can copy the settings of another bucket by clicking on the choose bucket button.
Checkbox block all public access can be enabled as we will use access key ID and secret access key to gain access.
In the following sections, you can leave the default settings and click create bucket.
After you create the bucket it will appear in the list of buckets.
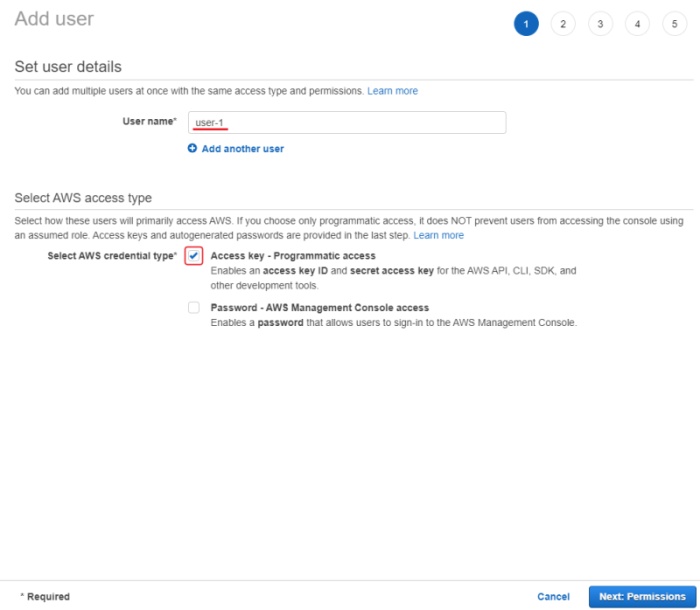
Create user and configure permissions
To access bucket you will need to create a user, to do this, go IAM
and click add users. You need to choose AWS access type, have an access key ID and secret access key.
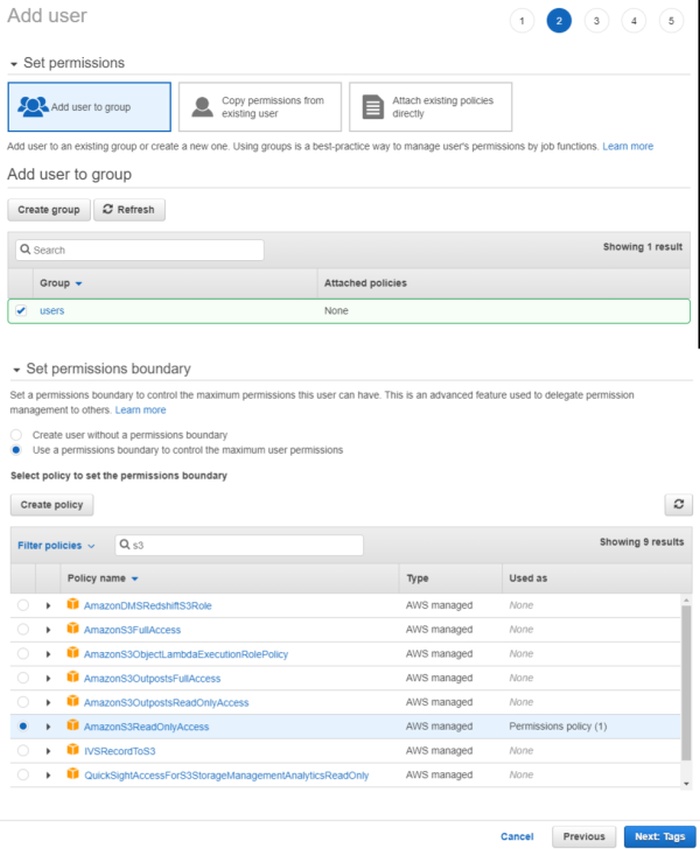
After pressing next button to configure permissions, you need to create a user group.
To do this click create a group, input the group name and select permission policies add AmazonS3ReadOnlyAccess
using the search (if you want the user you create to have write rights to bucket select AmazonS3FullAccess).
You can also add tags for the user (optional), and look again at the entered data. In the last step of creating a user,
you will be provided with access key ID and secret access key,
they will need to be used in CVAT when adding cloud storage.
First, create a Microsoft account by registering,
or you can use your GitHub account to log in. After signing up for Azure, you’ll need to choose a subscription plan,
you can choose a free 12-month subscription, but you’ll need to enter your credit card details to verify your identity.
To learn more about Azure, read documentation.
Create a storage account
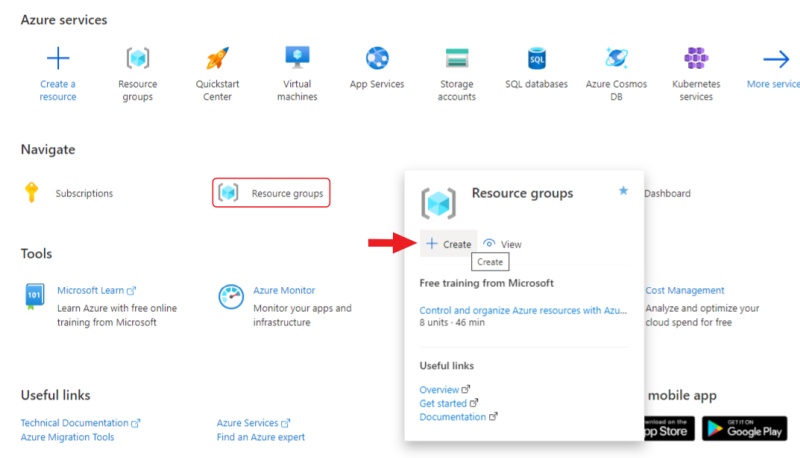
After registration, go to Azure portal.
Hover over the resource groups and click create in the window that appears.
Enter a name for the group and click review + create, check the entered data and click create.
After the resource group is created,
go to the resource groups page
and navigate to the resource group that you created.
Click create for create a storage account.
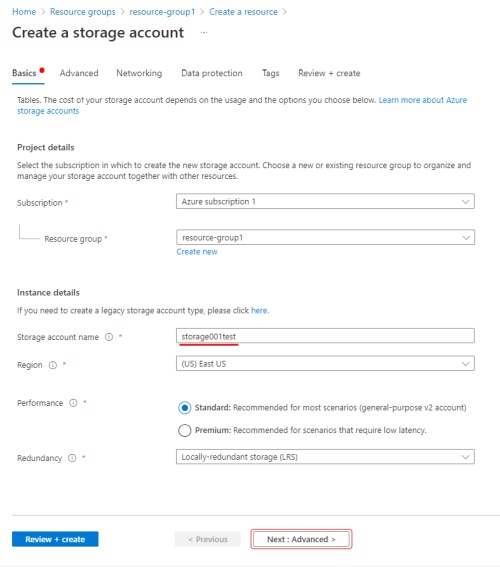
Basics
Enter storage account name (will be used in CVAT to access your container), select a region,
select performance in our case will be standard enough, select redundancy enough LRSmore about redundancy.
Click next to go to the advanced section.
Advanced
In the advanced section, you can change public access by disabling enable blob public access
to deny anonymous access to the container.
If you want to change public access you can find this switch in the configuration section of your storage account.
After that, go to the review section, check the entered data and click create.
You will be reached to the deployment page after the finished,
navigate to the resource by clicking on go to resource.
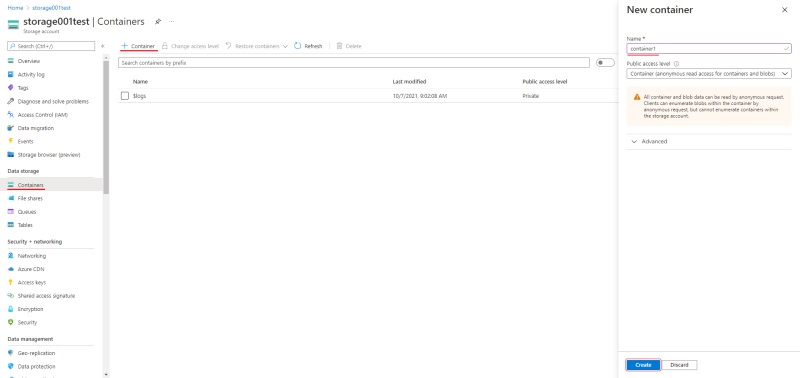
Create a container
Go to the containers section and create a new container. Enter the name of the container
(will be used in CVAT to access your container) and select container in public access level.
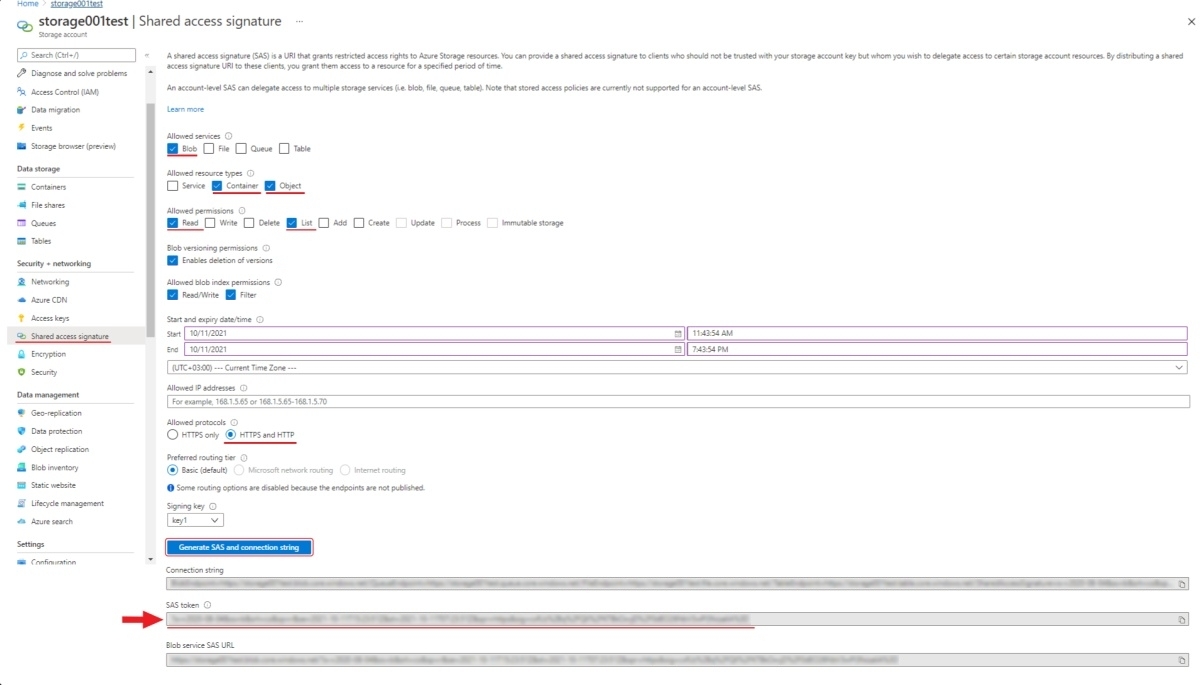
SAS token
Using the SAS token, you can securely transfer access to the container to other people by preconfiguring rights,
as well as the date/time of the starting and expiration of the token.
To generate a SAS token, go to Shared access signature section of your storage account.
Here you should enable Blob in the Allowed services, Container and Object in the Allowed resource types,
Read and List in the Allowed permissions, HTTPS and HTTP in the Allowed protocols,
also here you can set the date/time of the starting and expiration for the token. Click Generation SAS token.
and copy SAS token (will be used in CVAT to access your container).
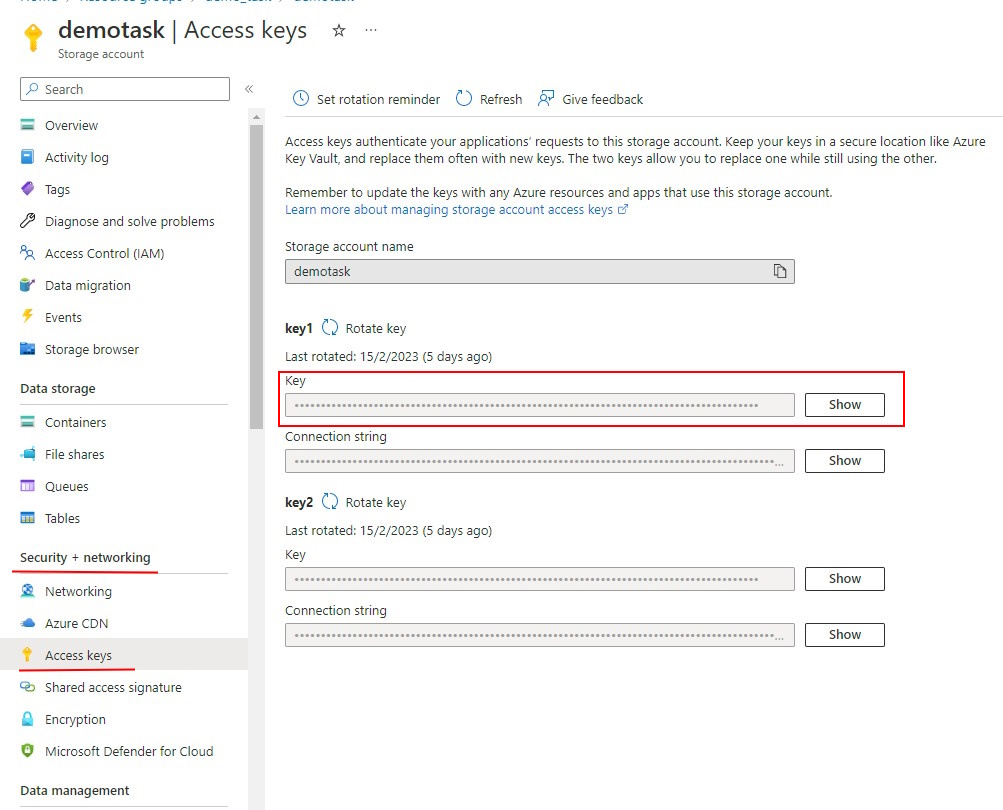
For personal use, you can enter the Access Key from the your storage account in the SAS Token field,
access key can be found in the security + networking section.
Click show keys to show the key.
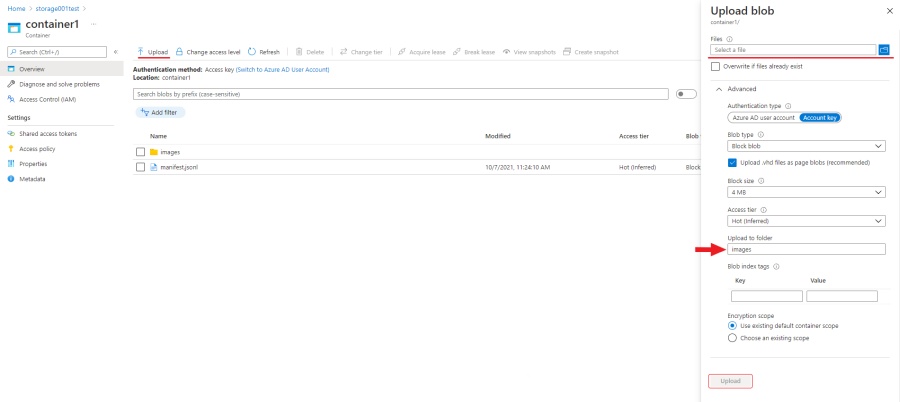
When the dataset is ready, go to your container and click upload.
Click select a files and select all images from the images folder
in the upload to folder item write the name of the folder in which you want to upload images in this case “images”.
Click upload, when the images are loaded you will need to upload a manifest file. When loading a manifest, you
need to make sure that the relative paths specified in the manifest file match the paths
to the files in the container. Click select a file and select manifest file, in order to upload file to the root
of the container leave blank upload to folder field.
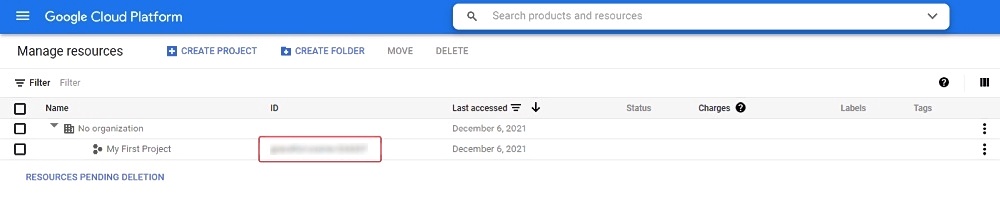
First, create a Google account, go to account login page and click Create account.
After, go to the Google Cloud page, click Get started, enter the required data
and accept the terms of service (you’ll need credit card information to register).
Create a bucket
Your first project will be created automatically, you can see it on the cloud resource manager page.
To create a bucket, go to the cloud storage page
and press Create bucket. Next, enter the name of the bucket, add labels if necessary, select the type of location
for example region and the location nearest to you, select storage class, when selecting access control
you can enable Enforce public access prevention on this bucket (if you plan to have anonymous access to your bucket,
it should be disabled) you can select Uniform or Fine-grained access control, if you need protection of your
object data select protect object data type. When all the information is entered click Create to create the bucket.
To upload files, you can simply drag and drop files and folders into a browser window
or use the upload folder and/or upload files.
Access permissions
To access Google Cloud Storage from CVAT you will need a Project ID
you can find it by going to cloud resource manager page
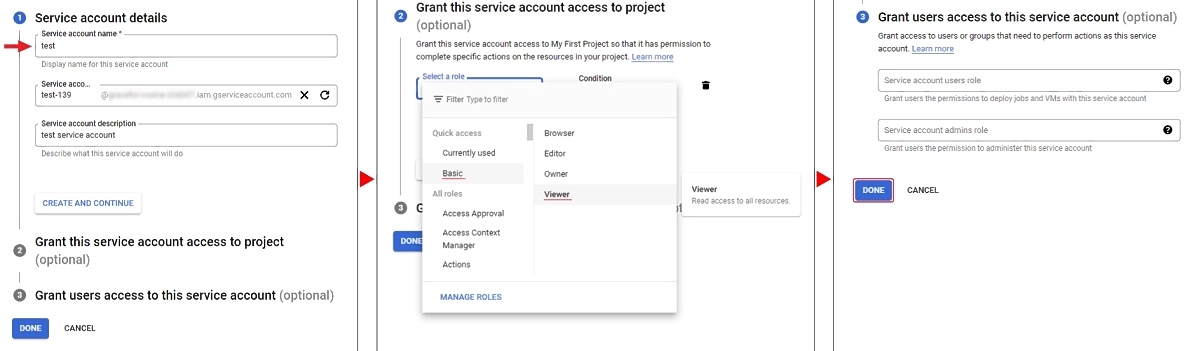
Create a service account and key file
To access your bucket you need a key file and a service account. To create a service account,
go to IAM & Admin/Service Accounts and press Create Service Account. Enter your account
name and click Create And Continue. Select a role for example Basic/Viewer.
Next, you can give access rights to the service account, to complete click Done.
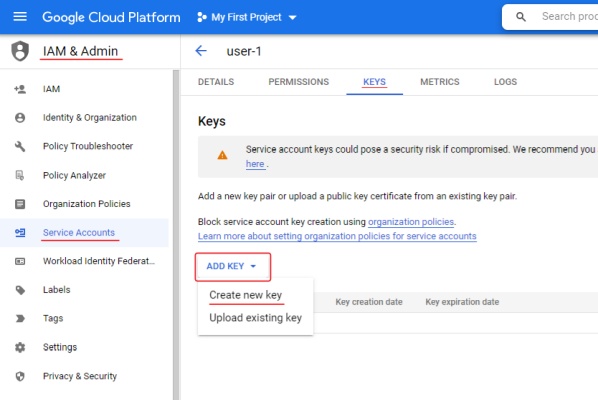
The account you created will appear in the service accounts list, open it and go to the Keys tab.
To create a key, click ADD and select Create new key, next you need to choose the key type JSON and select Create.
The key file will be downloaded automatically.
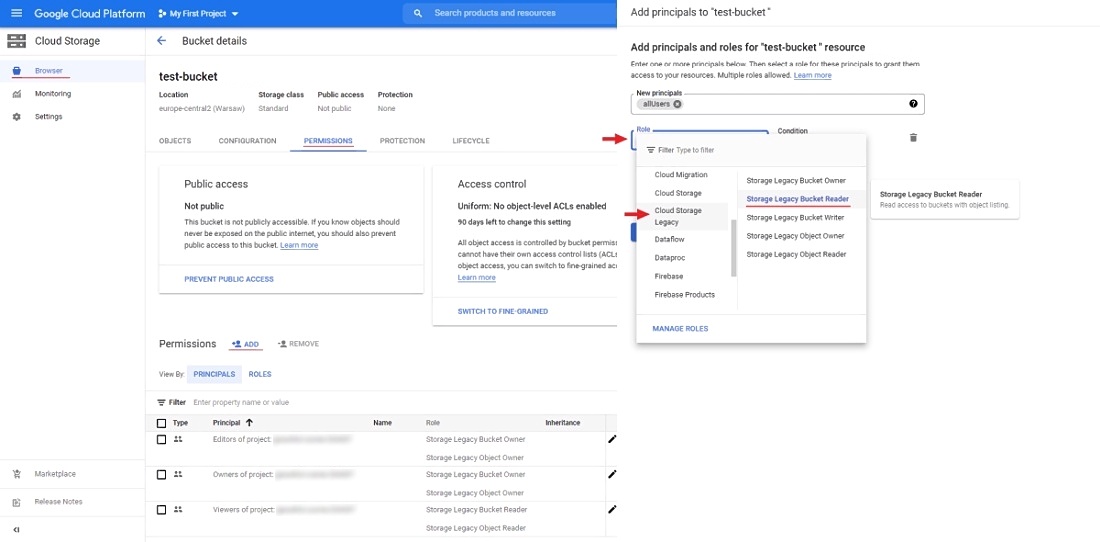
To configure anonymous access, open your bucket and go to the permissions tab click ADD to add new principals.
In new principals field specify allUsers, select role for example Cloud Storage Legacy/Storage Legacy Bucket Reader
and press SAVE.
Now you can attach new cloud storage into CVAT.
Attach new cloud storage
After you upload the dataset and manifest file to AWS-S3, Azure Blob Container or Google Cloud Storage
you will be able to attach a cloud storage. To do this, press the Attach new cloud storage
button on the Cloud storages page and fill out the following form:
Display name - the display name of the cloud storage.
Description (optional) - description of the cloud storage, appears when you click on the ? button
of an item on cloud storages page.
Key id and secret access key pair - available on IAM
to obtain an access key and a secret key, create a user using IAM and grant the appropriate rights learn more.
ACCESS KEY ID
SECRET ACCESS KEY ID
Anonymous access - for anonymous access, you need to enable public access to bucket.
Region - here you can choose a region from the list or add a new one. To get more information click
on ?.
SAS token - is located in the Shared access signature section of your Storage accountlearn more.
Anonymous access -
for anonymous access enable blob public access in the configuration section of your storage account.
in this case, you only need the storage account name to gain anonymous access.
Key file - you can drag a key file to the area attach a file
or click on the area to select the key file through the explorer. If the environment variable
GOOGLE_APPLICATION_CREDENTIALS is specified for an environment with a deployed CVAT instance, then it will
be used if you do not attach the key file
(more about GOOGLE_APPLICATION_CREDENTIALS).
Anonymous access - for anonymous access, you need to enable public access to bucket.
Location - here you can choose a region from the list or add a new one. To get more information click
on ?.
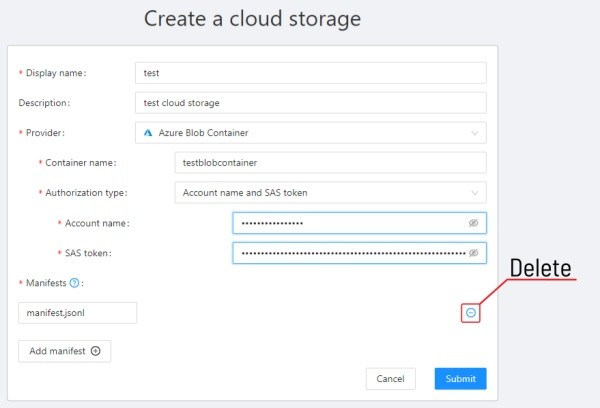
Manifest - the path to the manifest file on your cloud storage.
You can add multiple manifest files using the Add manifest button.
You can find on how to prepare dataset manifest here.
If you have data on the cloud storage and don’t want to download content locally, you can mount your
cloud storage as a share point according to that guide
and prepare manifest for the data.
To publish the cloud storage, click submit, after which it will be available on
the Cloud storages page.
Using AWS Data Exchange
Subscribe to data set
You can use AWS Data Exchange to add image datasets.
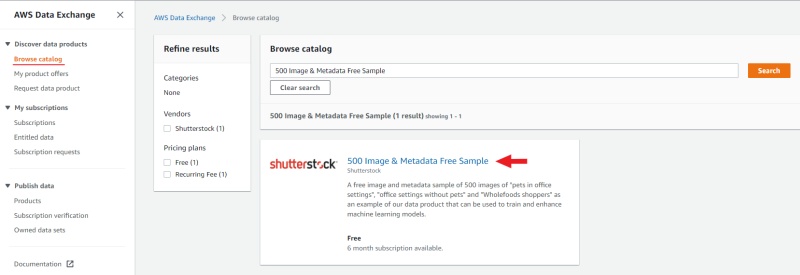
For example, consider adding a set of datasets 500 Image & Metadata Free Sample.
Go to browse catalog and use the search to find
500 Image & Metadata Free Sample, open the dataset page and click continue to subscribe,
you will be taken to the page complete subscription request, read the information provided
and click send subscription request to provider.
Export to bucket
After that, this dataset will appear in the
list subscriptions.
Now you need to export the dataset to Amazon S3.
First, let’s create a new one bucket similar to described above.
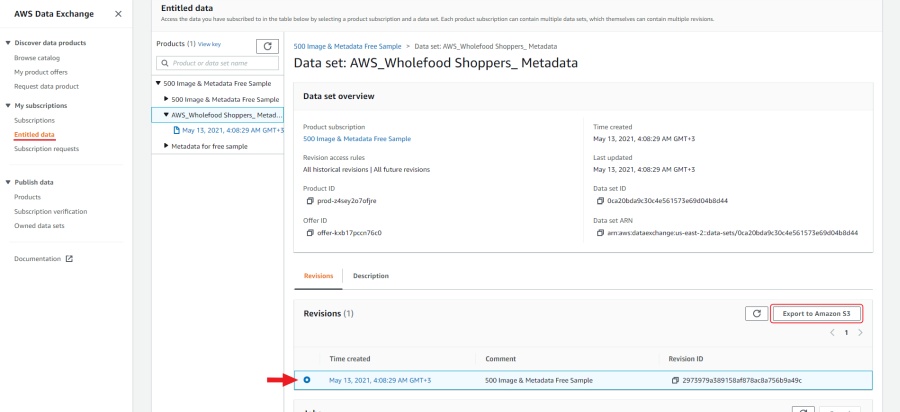
To export one of the datasets to a new bucket open it entitled data select one of the datasets,
select the corresponding revision and click export to Amazon S3
(please note that if bucket and dataset are located in different regions, export fees may apply).
In the window that appears, select the created bucket and click export.
Prepare manifest file
Now you need to prepare a manifest file. I used AWS cli and
script for prepare manifest file.
Perform the installation using the manual aws-shell,
I used aws-cli 1.20.49Python 3.7.9Windows 10.
You can configure credentials by running aws configure.
You will need to enter Access Key ID and Secret Access Key as well as region.
This section contains advanced documents for CVAT users
2.2.1 - Projects
Creating and exporting projects in CVAT.
Create project
At CVAT, you can create a project containing tasks of the same type.
All tasks related to the project will inherit a list of labels.
To create a project, go to the projects section by clicking on the Projects item in the top menu.
On the projects page, you can see a list of projects, use a search,
or create a new project by clicking Create New Project.
You can change: the name of the project, the list of labels
(which will be used for tasks created as parts of this project) and a link to the issue.
Once created, the project will appear on the projects page. To open a project, just click on it.
Here you can do the following:
Change the project’s title.
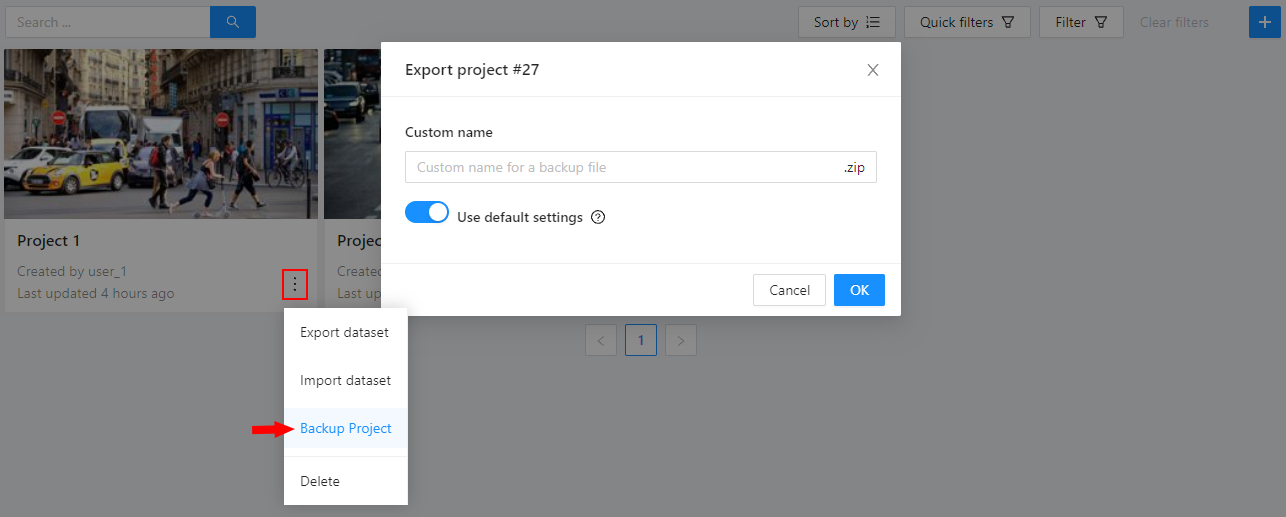
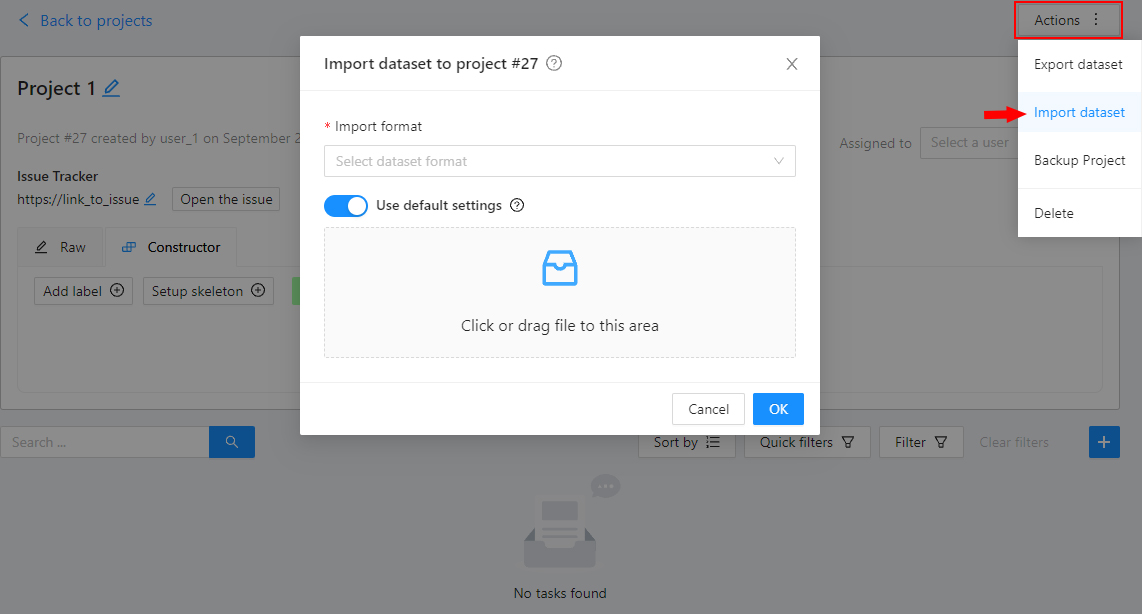
Open the Actions menu. Each button is responsible for a specific function in the Actions menu:
Export dataset/Import dataset - download/upload annotations or annotations and images in a specific format.
More information is available in the export/import datasets
section.
Backup project - make a backup of the project read more in the backup section.
Delete - remove the project and all related tasks.
Change issue tracker or open issue tracker if it is specified.
Change labels.
You can add new labels or add attributes for the existing labels in the Raw mode or the Constructor mode.
You can also change the color for different labels. By clicking Copy you can copy the labels to the clipboard.
Assigned to — is used to assign a project to a person.
Start typing an assignee’s name and/or choose the right person out of the dropdown list.
Tasks — is a list of all tasks for a particular project, with the ability to search for tasks in the project.
Read more about search.
It is possible to choose a subset for tasks in the project. You can use the available options
(Train, Test, Validation) or set your own.
2.2.2 - Organization
Using organization in CVAT.
Personal workspace
Your Personal workspace will display the tasks and projects you’ve created.
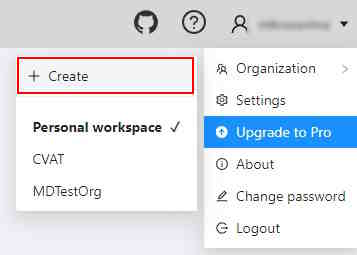
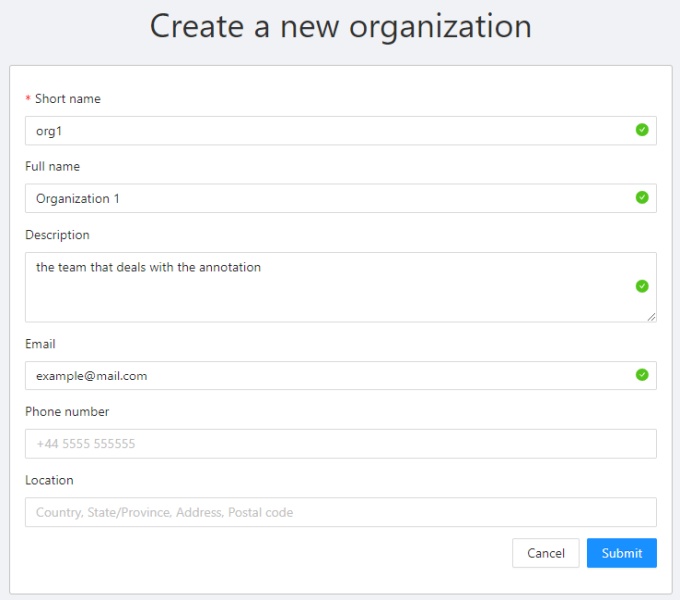
Create a new organization
To create an organization, open the user menu, go to Organization and click Create.
Fill in the required information to create your organization.
You need to enter a Short name of the organization, which will be displayed in the menu.
You can specify other fields: Full Name, Description and the organization contacts.
Of them will be visible on the organization settings page.
Organization page
To go to the organization page, open the user menu, go to Organization and click Settings.
Invite members into organization
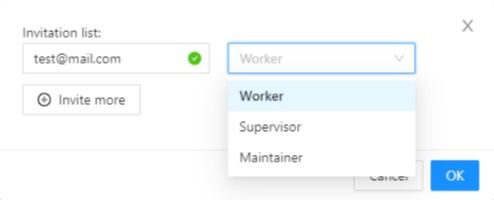
To add members, click Invite members. In the window that appears,
enter the email of the user you want to add and select the role (the role defines a set of rules):
Worker - workers have only access to tasks, projects, and jobs, assigned to them.
Supervisor - this role allows you to create and assign jobs, tasks and projects to members of the organization.
Maintainer - a member with this role has all the capabilities of the role supervisor,
sees all the tasks and the projects created by other members of the organization,
has full access to the Cloud Storages feature, and can modify members and their roles.
Owner - a role assigned to the creator of the organization with maximum capabilities.
In addition to roles, there are groups of users that are configured on the Admin page.
Read more about the roles in IAM system roles section.
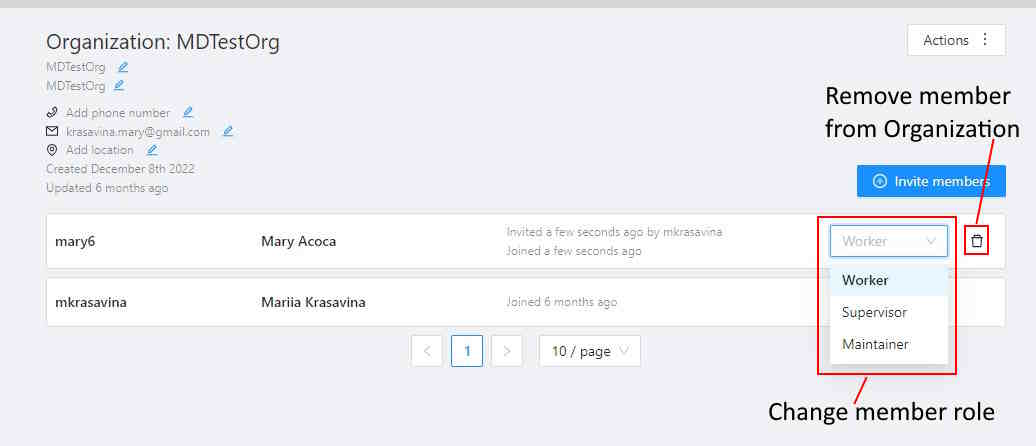
After you add members, they will appear on your organization settings page,
with each member listed and information about invitation details.
You can change a member’s role or remove a member at any time.
The member can leave the organization on his own by clicking Leave organization on the organization settings page.
Remove organization
You can remove an organization that you created.
Deleting an organization will delete all related resources (annotations, jobs, tasks, projects, cloud storages, ..).
In order to remove an organization, click Remove organization,
you will be asked to confirm the deletion by entering the short name of the organization.
2.2.3 - Search
Overview of available search options.
There are several options how to use the search.
Search within all fields (owner, assignee, task name, task status, task mode).
To execute enter a search string in search field.
Search for specific fields. How to perform:
owner: admin - all tasks created by the user who has the substring “admin” in his name
assignee: employee - all tasks which are assigned to a user who has the substring “employee” in his name
name: training - all tasks with the substring “training” in their names
mode: annotation or mode: interpolation - all tasks with images or videos.
status: annotation or status: validation or status: completed - search by status
id: 5 - task with id = 5.
Multiple filters. Filters can be combined (except for the identifier) using the keyword AND:
mode: interpolation AND owner: admin
mode: annotation and status: annotation
The search is case insensitive.
2.2.4 - Shape mode (advanced)
Advanced operations available during annotation in shape mode.
Occluded
Occlusion is an attribute used if an object is occluded by another object or
isn’t fully visible on the frame. Use Q shortcut to set the property
quickly.
Example: the three cars on the figure below should be labeled as occluded.
If a frame contains too many objects and it is difficult to annotate them
due to many shapes placed mostly in the same place, it makes sense
to lock them. Shapes for locked objects are transparent, and it is easy to
annotate new objects. Besides, you can’t change previously annotated objects
by accident. Shortcut: L.
2.2.5 - Track mode (advanced)
Advanced operations available during annotation in track mode.
Shapes that were created in the track mode, have extra navigation buttons.
These buttons help to jump to the previous/next keyframe.
The button helps to jump to the initial frame and to the last keyframe.
You can use the Split function to split one track into two tracks:
2.2.6 - 3D Object annotation (advanced)
Overview of advanced operations available when annotating 3D objects.
As well as 2D-task objects, 3D-task objects support the ability to change appearance, attributes,
properties and have an action menu. Read more in objects sidebar section.
Moving an object
If you hover the cursor over a cuboid and press Shift+N, the cuboid will be cut,
so you can paste it in other place (double-click to paste the cuboid).
Copying
As well as in 2D task you can copy and paste objects by Ctrl+C and Ctrl+V,
but unlike 2D tasks you have to place a copied object in a 3D space (double click to paste).
Image of the projection window
You can copy or save the projection-window image by left-clicking on it and selecting a “save image as” or “copy image”.
2.2.7 - Attribute annotation mode (advanced)
Advanced operations available in attribute annotation mode.
It is possible to handle lots of objects on the same frame in the mode.
It is more convenient to annotate objects of the same type. In this case you can apply
the appropriate filter. For example, the following filter will
hide all objects except person: label=="Person".
To navigate between objects (person in this case),
use the following buttons switch between objects in the frame on the special panel:
or shortcuts:
Tab — go to the next object
Shift+Tab — go to the previous object.
In order to change the zoom level, go to settings (press F3)
in the workspace tab and set the value Attribute annotation mode (AAM) zoom margin in px.
2.2.8 - Annotation with rectangles
To learn more about annotation using a rectangle, see the sections:
To rotate the rectangle, pull on the rotation point. Rotation is done around the center of the rectangle.
To rotate at a fixed angle (multiple of 15 degrees),
hold shift. In the process of rotation, you can see the angle of rotation.
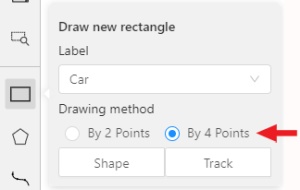
Annotation with rectangle by 4 points
It is an efficient method of bounding box annotation, proposed
here.
Before starting, you need to make sure that the drawing method by 4 points is selected.
Press Shape or Track for entering drawing mode. Click on four extreme points:
the top, bottom, left- and right-most physical points on the object.
Drawing will be automatically completed right after clicking the fourth point.
Press Esc to cancel editing.
2.2.9 - Annotation with polygons
Guide to creating and editing polygons.
2.2.9.1 - Manual drawing
It is used for semantic / instance segmentation.
Before starting, you need to select Polygon on the controls sidebar and choose the correct Label.
Click Shape to enter drawing mode.
There are two ways to draw a polygon: either create points by clicking or
by dragging the mouse on the screen while holding Shift.
Clicking points
Holding Shift+Dragging
When Shift isn’t pressed, you can zoom in/out (when scrolling the mouse
wheel) and move (when clicking the mouse wheel and moving the mouse), you can also
delete the previous point by right-clicking on it.
You can use the Selected opacity slider in the Objects sidebar to change the opacity of the polygon.
You can read more in the Objects sidebar section.
Press N again or click the Done button on the top panel for completing the shape.
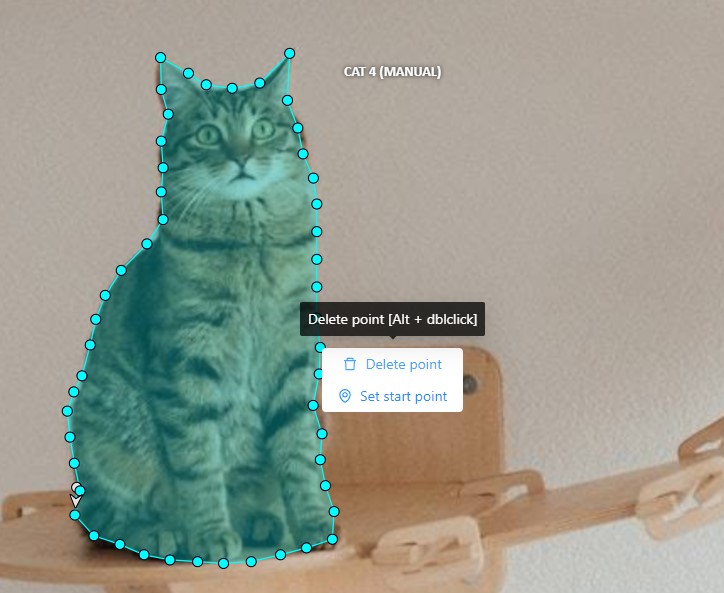
After creating the polygon, you can move the points or delete them by right-clicking and selecting Delete point
or clicking with pressed Alt key in the context menu.
2.2.9.2 - Drawing using automatic borders
You can use auto borders when drawing a polygon. Using automatic borders allows you to automatically trace
the outline of polygons existing in the annotation.
To do this, go to settings -> workspace tab and enable Automatic Bordering
or press Ctrl while drawing a polygon.
Start drawing / editing a polygon.
Points of other shapes will be highlighted, which means that the polygon can be attached to them.
Define the part of the polygon path that you want to repeat.
Click on the first point of the contour part.
Then click on any point located on part of the path. The selected point will be highlighted in purple.
Click on the last point and the outline to this point will be built automatically.
Besides, you can set a fixed number of points in the Number of points field, then
drawing will be stopped automatically. To enable dragging you should right-click
inside the polygon and choose Switch pinned property.
Below you can see results with opacity and black stroke:
If you need to annotate small objects, increase Image Quality to
95 in Create task dialog for your convenience.
2.2.9.3 - Edit polygon
To edit a polygon you have to click on it while holding Shift, it will open the polygon editor.
In the editor you can create new points or delete part of a polygon by closing the line on another point.
When Intelligent polygon cropping option is activated in the settings,
СVAT considers two criteria to decide which part of a polygon should be cut off during automatic editing.
The first criteria is a number of cut points.
The second criteria is a length of a cut curve.
If both criteria recommend to cut the same part, algorithm works automatically,
and if not, a user has to make the decision.
If you want to choose manually which part of a polygon should be cut off,
disable Intelligent polygon cropping in the settings.
In this case after closing the polygon, you can select the part of the polygon you want to leave.
To create a polygon in the track mode, click the Track button.
Create a polygon the same way as in the case of Annotation with polygons.
Press N or click the Done button on the top panel to complete the polygon.
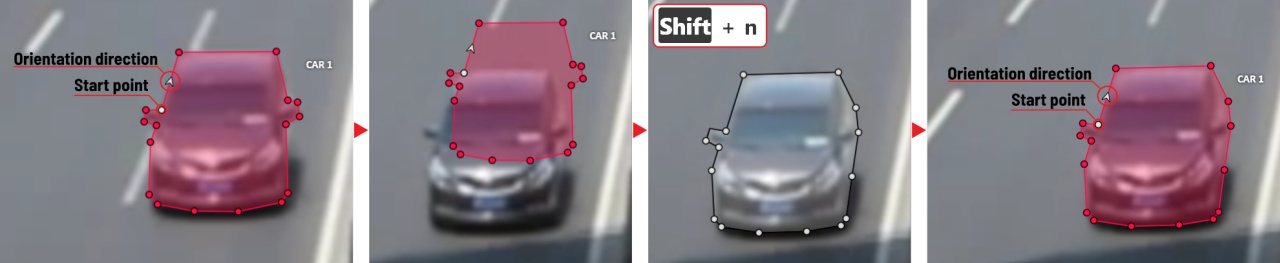
Pay attention to the fact that the created polygon has a starting point and a direction,
these elements are important for annotation of the following frames.
After going a few frames forward press Shift+N, the old polygon will disappear and you can create a new polygon.
The new starting point should match the starting point of the previously created polygon
(in this example, the top of the left mirror). The direction must also match (in this example, clockwise).
After creating the polygon, press N and the intermediate frames will be interpolated automatically.
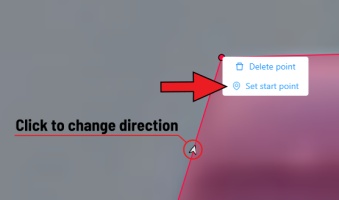
If you need to change the starting point, right-click on the desired point and select Set starting point.
To change the direction, right-click on the desired point and select switch orientation.
There is no need to redraw the polygon every time using Shift+N,
instead you can simply move the points or edit a part of the polygon by pressing Shift+Click.
2.2.9.5 - Creating masks
Cutting holes in polygons
Currently, CVAT does not support cutting transparent holes in polygons. However,
it is poissble to generate holes in exported instance and class masks.
To do this, one needs to define a background class in the task and draw holes
with it as additional shapes above the shapes needed to have holes:
The editor window:
Remember to use z-axis ordering for shapes by [-] and [+, =] keys.
Exported masks:
Notice that it is currently impossible to have a single instance number for
internal shapes (they will be merged into the largest one and then covered by
“holes”).
Creating masks
There are several formats in CVAT that can be used to export masks:
An example of exported masks (in the Segmentation Mask format):
Important notices:
Both boxes and polygons are converted into masks
Grouped objects are considered as a single instance and exported as a single
mask (label and attributes are taken from the largest object in the group)
Class colors
All the labels have associated colors, which are used in the generated masks.
These colors can be changed in the task label properties:
Label colors are also displayed in the annotation window on the right panel,
where you can show or hide specific labels
(only the presented labels are displayed):
A background class can be:
A default class, which is implicitly-added, of black color (RGB 0, 0, 0)
background class with any color (has a priority, name is case-insensitive)
Any class of black color (RGB 0, 0, 0)
To change background color in generated masks (default is black),
change background class color to the desired one.
2.2.10 - Annotation with polylines
Guide to annotating tasks using polylines.
It is used for road markup annotation etc.
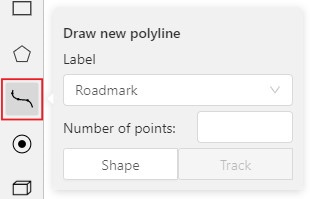
Before starting, you need to select the Polyline. You can set a fixed number of points
in the Number of points field, then drawing will be stopped automatically.
Click Shape to enter drawing mode. There are two ways to draw a polyline —
you either create points by clicking or by dragging a mouse on the screen while holding Shift.
When Shift isn’t pressed, you can zoom in/out (when scrolling the mouse wheel)
and move (when clicking the mouse wheel and moving the mouse), you can delete
previous points by right-clicking on it.
Press N again or click the Done button on the top panel to complete the shape.
You can delete a point by clicking on it with pressed Ctrl or right-clicking on a point
and selecting Delete point. Click with pressed Shift will open a polyline editor.
There you can create new points(by clicking or dragging) or delete part of a polygon closing
the red line on another point. Press Esc to cancel editing.
2.2.11 - Annotation with points
Guide to annotating tasks using single points or shapes containing multiple points.
2.2.11.1 - Points in shape mode
It is used for face, landmarks annotation etc.
Before you start you need to select the Points. If necessary you can set a fixed number of points
in the Number of points field, then drawing will be stopped automatically.
Click Shape to entering the drawing mode. Now you can start annotation of the necessary area.
Points are automatically grouped — all points will be considered linked between each start and finish.
Press N again or click the Done button on the top panel to finish marking the area.
You can delete a point by clicking with pressed Ctrl or right-clicking on a point and selecting Delete point.
Clicking with pressed Shift will open the points shape editor.
There you can add new points into an existing shape. You can zoom in/out (when scrolling the mouse wheel)
and move (when clicking the mouse wheel and moving the mouse) while drawing. You can drag an object after
it has been drawn and change the position of individual points after finishing an object.
2.2.11.2 - Linear interpolation with one point
You can use linear interpolation for points to annotate a moving object:
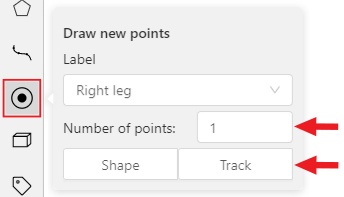
Before you start, select the Points.
Linear interpolation works only with one point, so you need to set Number of points to 1.
After that select the Track.
Click Track to enter the drawing mode left-click to create a point
and after that shape will be automatically completed.
Move forward a few frames and move the point to the desired position,
this way you will create a keyframe and intermediate frames will be drawn automatically.
You can work with this object as with an interpolated track: you can hide it using the Outside,
move around keyframes, etc.
This way you’ll get linear interpolation using the Points.
2.2.12 - Annotation with ellipses
Guide to annotating tasks using ellipses.
It is used for road sign annotation etc.
First of all you need to select the ellipse on the controls sidebar.
Choose a Label and click Shape or Track to start drawing. An ellipse can be created the same way as
a rectangle, you need to specify two opposite points,
and the ellipse will be inscribed in an imaginary rectangle. Press N or click the Done button on the top panel
to complete the shape.
You can rotate ellipses using a rotation point in the same way as
rectangles.
2.2.13 - Annotation with cuboids
Guide to creating and editing cuboids.
It is used to annotate 3 dimensional objects such as cars, boxes, etc…
Currently the feature supports one point perspective and has the constraint
where the vertical edges are exactly parallel to the sides.
2.2.13.1 - Creating the cuboid
Before you start, you have to make sure that Cuboid is selected
and choose a drawing method ”from rectangle” or “by 4 points”.
Drawing cuboid by 4 points
Choose a drawing method “by 4 points” and click Shape to enter the drawing mode. There are many ways to draw a cuboid.
You can draw the cuboid by placing 4 points, after that the drawing will be completed automatically.
The first 3 points determine the plane of the cuboid while the last point determines the depth of that plane.
For the first 3 points, it is recommended to only draw the 2 closest side faces, as well as the top and bottom face.
A few examples:
Drawing cuboid from rectangle
Choose a drawing method “from rectangle” and click Shape to enter the drawing mode.
When you draw using the rectangle method, you must select the frontal plane of the object using the bounding box.
The depth and perspective of the resulting cuboid can be edited.
Example:
2.2.13.2 - Editing the cuboid
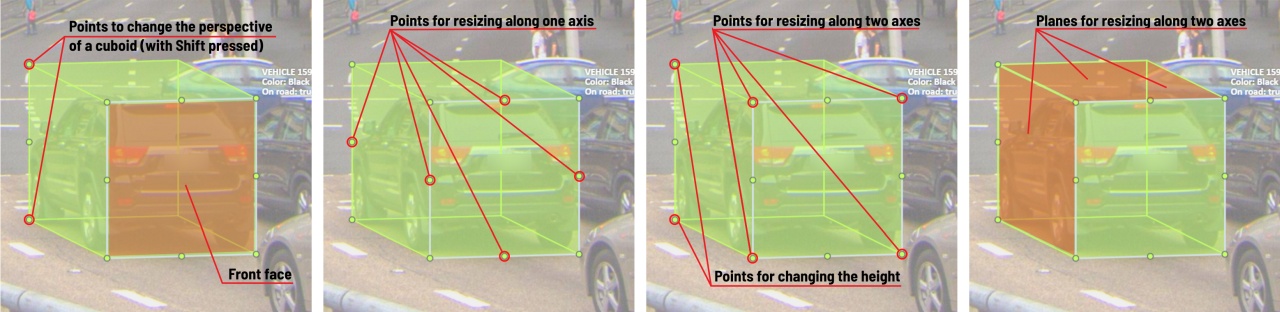
The cuboid can be edited in multiple ways: by dragging points, by dragging certain faces or by dragging planes.
First notice that there is a face that is painted with gray lines only, let us call it the front face.
You can move the cuboid by simply dragging the shape behind the front face.
The cuboid can be extended by dragging on the point in the middle of the edges.
The cuboid can also be extended up and down by dragging the point at the vertices.
To draw with perspective effects it should be assumed that the front face is the closest to the camera.
To begin simply drag the points on the vertices that are not on the gray/front face while holding Shift.
The cuboid can then be edited as usual.
If you wish to reset perspective effects, you may right click on the cuboid,
and select Reset perspective to return to a regular cuboid.
The location of the gray face can be swapped with the adjacent visible side face.
You can do it by right clicking on the cuboid and selecting Switch perspective orientation.
Note that this will also reset the perspective effects.
Certain faces of the cuboid can also be edited,
these faces are: the left, right and dorsal faces, relative to the gray face.
Simply drag the faces to move them independently from the rest of the cuboid.
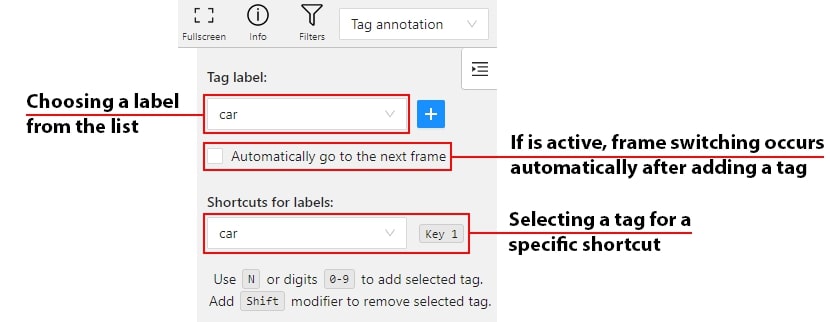
It is used to annotate frames, tags are not displayed in the workspace.
Before you start, open the drop-down list in the top panel and select Tag annotation.
The objects sidebar will be replaced with a special panel for working with tags.
Here you can select a label for a tag and add it by clicking on the Add tag button.
You can also customize hotkeys for each label.
If you need to use only one label for one frame, then enable the Automatically go to the next frame
checkbox, then after you add the tag the frame will automatically switch to the next.
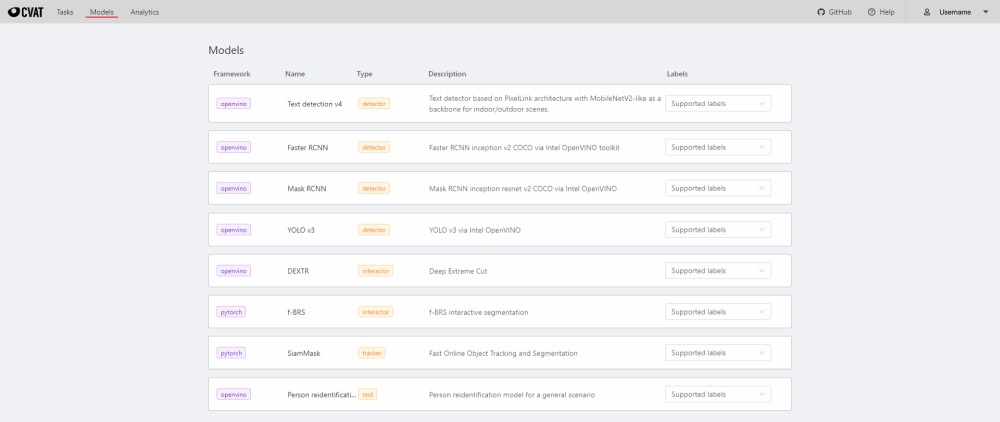
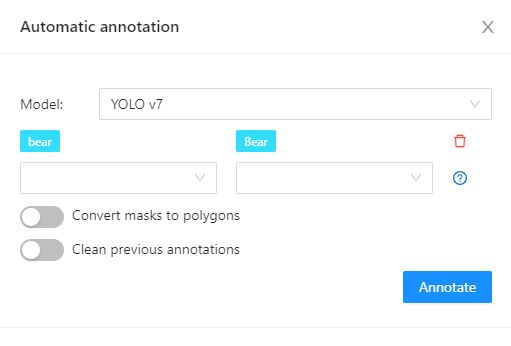
The Models page contains a list of deep learning (DL) models deployed for semi-automatic and automatic annotation.
To open the Models page, click the Models button on the navigation bar.
The list of models is presented in the form of a table. The parameters indicated for each model are the following:
interactor - used for semi-automatic shape annotation (available in interactors)
tracker - used for semi-automatic track annotation (available in trackers)
reid - used to combine individual objects into a track (available in automatic annotation)
Description - brief description of the model
Labels - list of the supported labels (only for the models of the detectors type)
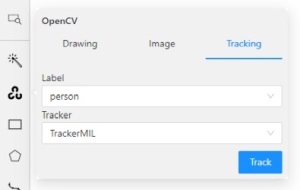
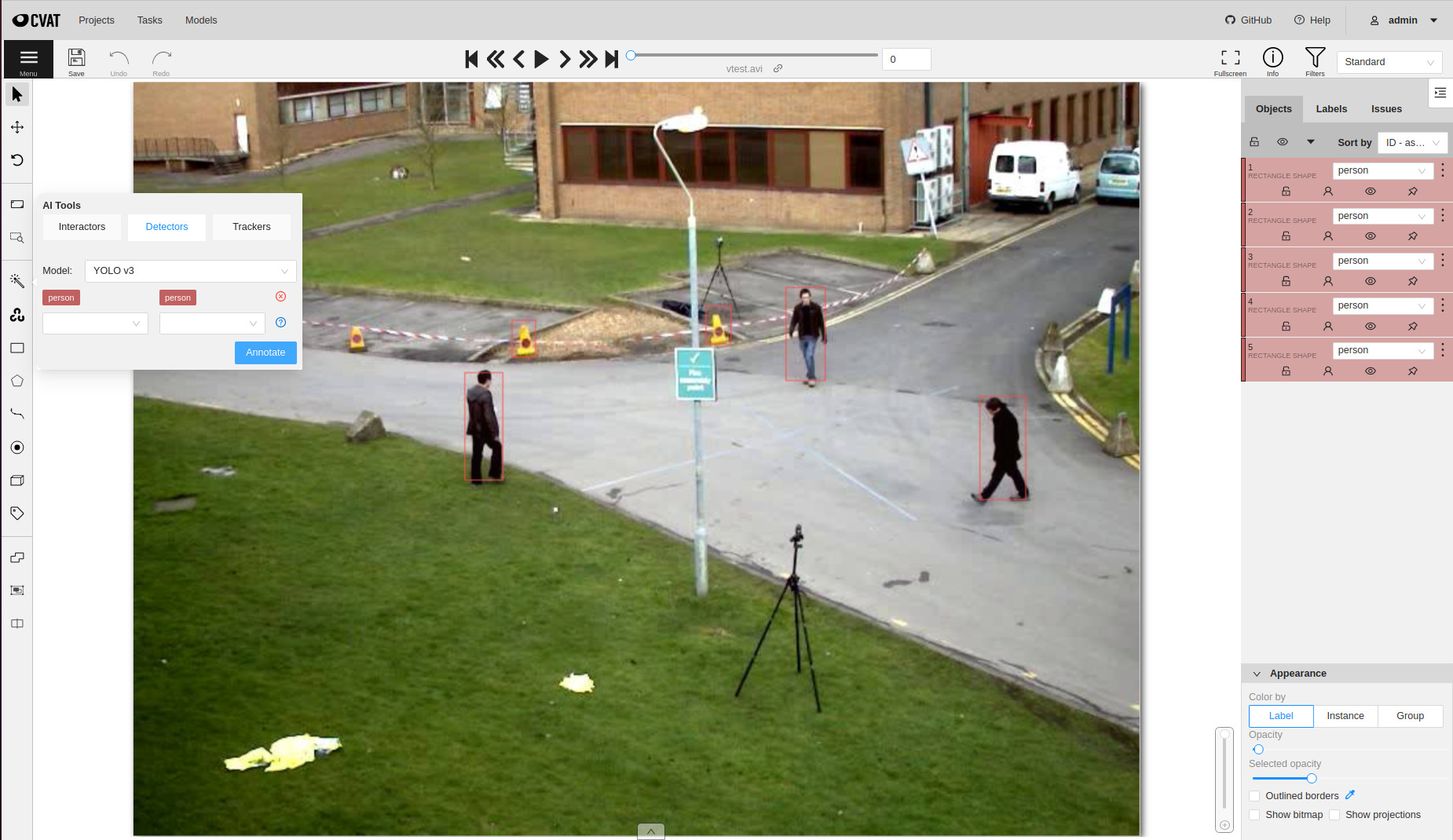
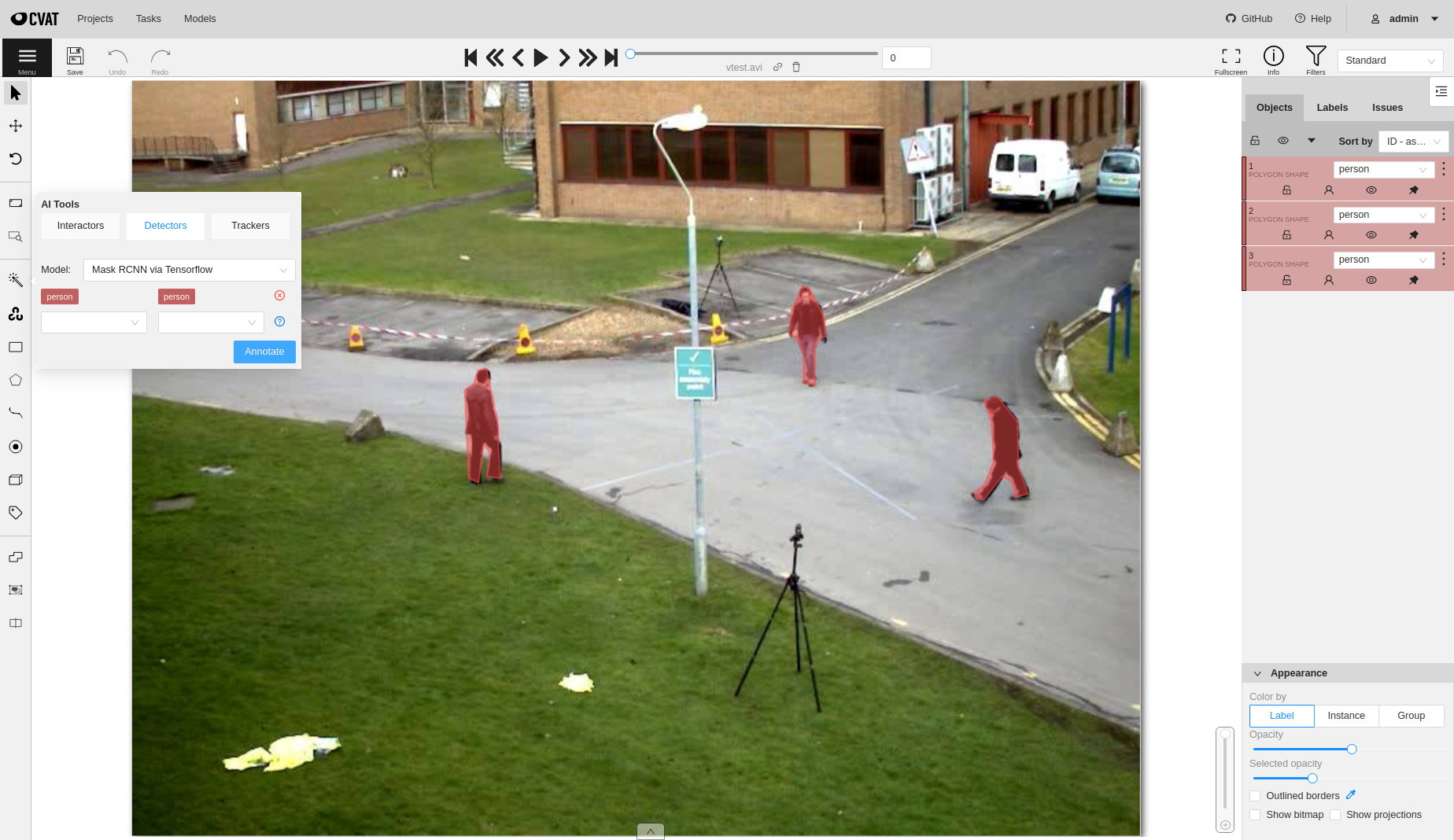
2.2.16 - AI Tools
Overview of semi-automatic and automatic annotation tools available in CVAT.
The tool is designed for semi-automatic and automatic annotation using DL models.
The tool is available only if there is a corresponding model.
For more details about DL models read the Models section.
Interactors
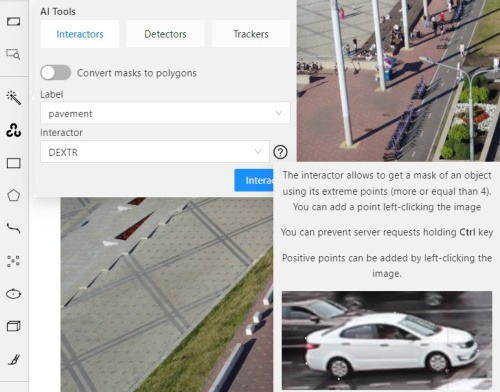
Interactors are used to create a polygon semi-automatically.
Supported DL models are not bound to the label and can be used for any objects.
To create a polygon usually you need to use regular or positive points.
For some kinds of segmentation negative points are available.
Positive points are the points related to the object.
Negative points should be placed outside the boundary of the object.
In most cases specifying positive points alone is enough to build a polygon.
A list of available out-of-the-box interactors is placed below.
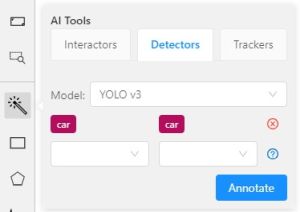
Before you start, select the magic wand on the controls sidebar and go to the Interactors tab.
Then select a label for the polygon and a required DL model. To view help about each of the
models, you can click the Question mark icon.
Click Interact to enter the interaction mode. Depending on the selected model,
the method of markup will also differ.
Now you can place positive and/or negative points. The IOG model also uses a rectangle.
Left click creates a positive point and right click creates a negative point.
After placing the required number of points (the number is different depending on the model),
the request will be sent to the server and when the process is complete a polygon will be created.
If you are not satisfied with the result, you can set additional points or remove points.
To delete a point, hover over the point you want to delete, if the point can be deleted,
it will enlarge and the cursor will turn into a cross, then left-click on the point.
If you want to postpone the request and create a few more points, hold down Ctrl and continue (the Block
button on the top panel will turn blue), the request will be sent after the key is released.
In the process of drawing, you can select the number of points in the polygon using the switch.
You can use the Selected opacity slider in the Objects sidebar to change the opacity of the polygon.
You can read more in the Objects sidebar section.
To finish interaction, click on the Done button on the top panel or press N on your keyboard.
When the object is finished, you can edit it like a polygon.
You can read about editing polygons in the Annotation with polygons section.
Deep extreme cut (DEXTR)
This is an optimized version of the original model, introduced at the end of 2017.
It uses the information about extreme points of an object to get its mask. The mask then converted to a polygon.
For now this is the fastest interactor on CPU.
Feature backpropagating refinement scheme (f-BRS)
The model allows to get a mask for an object using positive points
(should be left-clicked on the foreground), and negative points
(should be right-clicked on the background, if necessary).
It is recommended to run the model on GPU, if possible.
High Resolution Net (HRNet)
The model allows to get a mask for an object using positive points
(should be left-clicked on the foreground), and negative points
(should be right-clicked on the background, if necessary).
It is recommended to run the model on GPU, if possible.
Inside-Outside-Guidance
The model uses a bounding box and inside/outside points to create a mask.
First of all, you need to create a bounding box, wrapping the object.
Then you need to use positive and negative points to say the model where is a foreground,
and where is a background. Negative points are optional.
Detectors
Detectors are used to automatically annotate one frame. Supported DL models are suitable only for certain labels.
Before you start, click the magic wand on the controls sidebar and select the Detectors tab.
You need to match the labels of the DL model (left column) with the labels in your task (right column).
Then click Annotate.
This action will automatically annotates one frame.
In the Automatic annotation section you can read
how to make automatic annotation of all frames.
Mask RCNN
The model generates polygons for each instance of an object in the image.
Faster RCNN
The model generates bounding boxes for each instance of an object in the image. In this model,
RPN and Fast R-CNN are combined into a single network.
Trackers
Trackers are used to automatically annotate an object using bounding box.
Supported DL models are not bound to the label and can be used for any objects.
Before you start, select the magic wand on the controls sidebar and go to the Trackers tab.
Then select a Label and Tracker for the object and click Track. Then annotate the desired objects with the
bounding box in the first frame.
All annotated objects will be automatically tracked when you move to the next frame.
For tracking, use Next button on the top panel or the F button to move on to the next frame.
You can enable/disable tracking using tracker switcher on sidebar.
Trackable objects have indication on canvas with a model indication.
You can monitoring the process by the messages appearing at the top.
If you change one or more objects, before moving to the next frame, you will see a message that
the objects states initialization is taking place. The objects that you do not change are already on the server
and therefore do not require initialization. After the objects are initialized, tracking will occur.
SiamMask
Fast online Object Tracking and Segmentation. Tracker is able to track different objects in one server request.
Trackable object will be tracked automatically if the previous frame was
a latest keyframe for the object. Have tracker indication on canvas. SiamMask tracker supported CUDA.
If you plan to track simple non-overlapping objects consider using fast client-side TrackerMIL from OpenCV.
2.2.17 - OpenCV tools
Guide to using Computer Vision algorithms during annotation.
The tool based on Open CV Computer Vision library
which is an open-source product that includes many CV algorithms.
Some of these algorithms can be used to simplify the annotation process.
First step to work with OpenCV is to load it into CVAT. Click on the toolbar icon, then click Load OpenCV.
Once it is loaded, the tool’s functionality will be available.
Intelligent scissors
Intelligent scissors is an CV method of creating a polygon
by placing points with automatic drawing of a line between them.
The distance between the adjacent points is limited by the threshold of action,
displayed as a red square which is tied to the cursor.
First, select the label and then click on the intelligent scissors button.
Create the first point on the boundary of the allocated object.
You will see a line repeating the outline of the object.
Place the second point, so that the previous point is within the restrictive threshold.
After that a line repeating the object boundary will be automatically created between the points.
To increase or lower the action threshold, hold Ctrl and scroll the mouse wheel.
Increasing action threshold will affect the performance.
During the drawing process you can remove the last point by clicking on it with the left mouse button.
You can also create a boundary manually (like when
creating a polygon) by temporarily disabling
the automatic line creation. To do that, switch blocking on by pressing Ctrl.
In the process of drawing, you can select the number of points in the polygon using the switch.
You can use the Selected opacity slider in the Objects sidebar to change the opacity of the polygon.
You can read more in the Objects sidebar section.
Once all the points are placed, you can complete the creation of the object
by clicking on the Done button on the top panel or press N on your keyboard.
As a result, a polygon will be created (read more about the polygons in the annotation with polygons).
Histogram Equalization
Histogram equalization is an CV method that improves contrast in an image in order to stretch out the intensity range.
This method usually increases the global contrast of images when its usable data
is represented by close contrast values.
It is useful in images with backgrounds and foregrounds that are both bright or both dark.
First, select the image tab and then click on histogram equalization button.
Then contrast of current frame will be improved.
If you change frame, it will be equalized too.
You can disable equalization by clicking histogram equalization button again.
TrackerMIL
Trackers are used to automatically annotate an object on video.
The TrackerMIL model is not bound to labels and can be used for any object.
Before you start, select the OpenCV tools on the controls sidebar and go to the Trackers tab.
Then select a Label and Tracker for the object and click Track. Then annotate the desired objects with the
bounding box in the first frame.
All annotated objects will be automatically tracked when you move to the next frame.
For tracking, use Next button on the top panel or the F button to move on to the next frame.
You can enable/disable tracking using tracker switcher on sidebar.
Trackable objects have indication on canvas with a model indication.
You can follow the tracking by the messages appearing at the top.
2.2.18 - Automatic annotation
Guide to using the automatic annotation of tasks.
Automatic Annotation is used for creating preliminary annotations.
To use Automatic Annotation you need a DL model. You can use primary models or models uploaded by a user.
You can find the list of available models in the Models section.
To launch automatic annotation, you should open the dashboard and find a task which you want to annotate.
Then click the Actions button and choose option Automatic Annotation from the dropdown menu.
In the dialog window select a model you need. DL models are created for specific labels, e.g.
the Crossroad model was taught using footage from cameras located above the highway and it is best to
use this model for the tasks with similar camera angles.
If it’s necessary select the Clean old annotations checkbox.
Adjust the labels so that the task labels will correspond to the labels of the DL model.
For example, let’s consider a task where you have to annotate labels “car” and “person”.
You should connect the “person” label from the model to the “person” label in the task.
As for the “car” label, you should choose the most fitting label available in the model - the “vehicle” label.
The task requires to annotate cars only and choosing the “vehicle” label implies annotation of all vehicles,
in this case using auto annotation will help you complete the task faster.
Click Submit to begin the automatic annotation process.
At runtime - you can see the percentage of completion.
You can cancel the automatic annotation by clicking on the Cancelbutton.
The end result of an automatic annotation is an annotation with separate rectangles (or other shapes)
You can combine separate bounding boxes into tracks using the Person reidentification model.
To do this, click on the automatic annotation item in the action menu again and select the model
of the ReID type (in this case the Person reidentification model).
You can set the following parameters:
Model Threshold is a maximum cosine distance between objects’ embeddings.
Maximum distance defines a maximum radius that an object can diverge between adjacent frames.
You can remove false positives and edit tracks using Split and Merge functions.
2.2.19 - Backup Task and Project
In CVAT you can backup tasks and projects.
This can be used to backup a task or project on your PC or to transfer to another server.
Backup
To backup a task or project, open the action menu and select Backup Task or Backup Project.
Backup structure
As a result, you’ll get a zip archive containing data,
task or project and task specification and annotations with the following structure:
Sly Point Cloud Format 1.0 - Supervisely Point Cloud dataset
To download images with the dataset, tick the Save images box.
(Optional) To name the resulting archive, use the Custom name field.
Import dataset
You can import dataset only to a project. In this case, the data will be split into subsets.
To import a dataset, do the following on the Project page:
Open the Actions menu.
Press the Import dataset button.
Select the dataset format (if you did not specify a custom name during export,
the format will be in the archive name).
Drag the file to the file upload area or click on the upload area to select the file through the explorer.
During the import process, you will be able to track the progress of the import.
Upload annotations
In the task or job you can upload an annotation. For this select the item Upload annotation
in the menu Action of the task or in the job Menu on the Top panel select the format in which you plan
to upload the annotation and select the annotation file or archive via explorer.
2.2.21 - Task synchronization with a repository
Notice: this feature works only if a git repository was specified when the task was created.
At the end of the annotation process, a task is synchronized by clicking
Synchronize on the task page. If the synchronization is successful,
the button will change to Sychronized in blue:
The annotation is now in the repository in a temporary branch.
The next step is to go to the repository and manually create a pull request to the main branch.
After merging the PR, when the annotation is saved in the main branch,
the button changes to Merged and is highlighted in green.
If annotation in the task does not correspond annotations in the repository, the sync button will turn red:
Uploaded file: an XML file or a ZIP file of the structures above
2.2.22.2 -
Datumaro format
Datumaro is a tool, which can
help with complex dataset and annotation transformations, format conversions,
dataset statistics, merging, custom formats etc. It is used as a provider
of dataset support in CVAT, so basically, everything possible in CVAT
is possible in Datumaro too, but Datumaro can offer dataset operations.
supported annotations: any 2D shapes, labels
supported attributes: any
Import annotations in Datumaro format
Uploaded file: a zip archive of the following structure:
<archive_name>.zip/
└── annotations/
├── subset1.json # fully description of classes and all dataset items └── subset2.json # fully description of classes and all dataset items
JSON annotations files in the annotations directory should have similar structure:
Downloaded file: a zip archive with the structure described here
supported annotations: Polygons, Rectangles
supported attributes:
is_crowd (checkbox or integer with values 0 and 1) -
specifies that the instance (an object group) should have an
RLE-encoded mask in the segmentation field. All the grouped shapes
are merged into a single mask, the largest one defines all
the object properties
score (number) - the annotation score field
arbitrary attributes - will be stored in the attributes annotation section
It must be possible for CVAT to match the frame name and file name
from annotation .xml file (the filename tag, e. g.
<filename>2008_004457.jpg</filename> ).
There are 2 options:
full match between frame name and file name from annotation .xml
(in cases when task was created from images or image archive).
match by frame number. File name should be <number>.jpg
or frame_000000.jpg. It should be used when task was created from video.
Segmentation mask export
Downloaded file: a zip archive of the following structure:
taskname.zip/
├── labelmap.txt # optional, required for non-VOC labels├── ImageSets/
│ └── Segmentation/
│ └── default.txt # list of image names without extension├── SegmentationClass/ # merged class masks│ ├── image1.png
│ └── image2.png
└── SegmentationObject/ # merged instance masks ├── image1.png
└── image2.png
# labelmap.txt# label : color (RGB) : 'body' parts : actionsbackground:0,128,0::
aeroplane:10,10,128::
bicycle:10,128,0::
bird:0,108,128::
boat:108,0,100::
bottle:18,0,8::
bus:12,28,0::
Mask is a png image with 1 or 3 channels where each pixel
has own color which corresponds to a label.
Colors are generated following to Pascal VOC algorithm.
(0, 0, 0) is used for background by default.
supported shapes: Rectangles, Polygons
Segmentation mask import
Uploaded file: a zip archive of the following structure:
It is also possible to import grayscale (1-channel) PNG masks.
For grayscale masks provide a list of labels with the number of lines equal
to the maximum color index on images. The lines must be in the right order
so that line index is equal to the color index. Lines can have arbitrary,
but different, colors. If there are gaps in the used color
indices in the annotations, they must be filled with arbitrary dummy labels.
Example:
q:0,128,0:: # color index 0
aeroplane:10,10,128:: # color index 1
_dummy2:2,2,2:: # filler for color index 2
_dummy3:3,3,3:: # filler for color index 3
boat:108,0,100:: # color index 3
...
_dummy198:198,198,198:: # filler for color index 198
_dummy199:199,199,199:: # filler for color index 199
...
the last label:12,28,0:: # color index 200
supported shapes: Polygons
How to create a task from Pascal VOC dataset
Download the Pascal Voc dataset (Can be downloaded from the
PASCAL VOC website)
Create a CVAT task with the following labels:
aeroplane bicycle bird boat bottle bus car cat chair cow diningtable
dog horse motorbike person pottedplant sheep sofa train tvmonitor
You can add ~checkbox=difficult:false ~checkbox=truncated:false
attributes for each label if you want to use them.
Downloaded file: a zip archive with following structure:
archive.zip/
├── obj.data
├── obj.names
├── obj_<subset>_data
│ ├── image1.txt
│ └── image2.txt
└── train.txt # list of subset image paths# the only valid subsets are: train, valid# train.txt and valid.txt:obj_<subset>_data/image1.jpg
obj_<subset>_data/image2.jpg
# obj.data:classes=3# optionalnames= obj.names
train= train.txt
valid= valid.txt # optionalbackup= backup/ # optional# obj.names:cat
dog
airplane
# image_name.txt:# label_id - id from obj.names# cx, cy - relative coordinates of the bbox center# rw, rh - relative size of the bbox# label_id cx cy rw rh1 0.3 0.8 0.1 0.3
2 0.7 0.2 0.3 0.1
Each annotation *.txt file has a name that corresponds to the name of
the image file (e. g. frame_000001.txt is the annotation
for the frame_000001.jpg image).
The *.txt file structure: each line describes label and bounding box
in the following format label_id cx cy w h.
obj.names contains the ordered list of label names.
YOLO import
Uploaded file: a zip archive of the same structure as above
It must be possible to match the CVAT frame (image name)
and annotation file name. There are 2 options:
full match between image name and name of annotation *.txt file
(in cases when a task was created from images or archive of images).
match by frame number (if CVAT cannot match by name). File name
should be in the following format <number>.jpg .
It should be used when task was created from a video.
How to create a task from YOLO formatted dataset (from VOC for example)
Follow the official guide(see Training YOLO on VOC section)
and prepare the YOLO formatted annotation files.
Zip train images
zip images.zip -j -@ < train.txt
Create a CVAT task with the following labels:
aeroplane bicycle bird boat bottle bus car cat chair cow diningtable dog
horse motorbike person pottedplant sheep sofa train tvmonitor
Select images. zip as data. Most likely you should use share
functionality because size of images. zip is more than 500Mb.
See Creating an annotation task
guide for details.
Create obj.names with the following content:
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
Zip all label files together (we need to add only label files that correspond to the train subset)
cat train.txt |whileread p;doecho${p%/*/*}/labels/${${p##*/}%%.*}.txt;done| zip labels.zip -j -@ obj.names
Click Upload annotation button, choose YOLO 1.1 and select the zip
TFRecord is a very flexible format, but we try to correspond the
format that used in
TF object detection
with minimal modifications.
Used feature description:
image_feature_description={'image/filename':tf.io.FixedLenFeature([],tf.string),'image/source_id':tf.io.FixedLenFeature([],tf.string),'image/height':tf.io.FixedLenFeature([],tf.int64),'image/width':tf.io.FixedLenFeature([],tf.int64),# Object boxes and classes.'image/object/bbox/xmin':tf.io.VarLenFeature(tf.float32),'image/object/bbox/xmax':tf.io.VarLenFeature(tf.float32),'image/object/bbox/ymin':tf.io.VarLenFeature(tf.float32),'image/object/bbox/ymax':tf.io.VarLenFeature(tf.float32),'image/object/class/label':tf.io.VarLenFeature(tf.int64),'image/object/class/text':tf.io.VarLenFeature(tf.string),}
TFRecord export
Downloaded file: a zip archive with following structure:
cat <path to VOCdevkit>/VOC2007/ImageSets/Main/train.txt |whileread p;doecho <path to VOCdevkit>/VOC2007/JPEGImages/${p}.jpg ;done| zip images.zip -j -@
Create a CVAT task with the following labels:
aeroplane bicycle bird boat bottle bus car cat chair cow diningtable dog horse motorbike person pottedplant sheep sofa train tvmonitor
Downloaded file: a zip archive of the following structure:
taskname.zip/
├── bounding_box_<any_subset_name>/
│ └── image_name_1.jpg
└── query
├── image_name_2.jpg
└── image_name_3.jpg
# if we keep only annotation:taskname.zip/
└── images_<any_subset_name>.txt
# images_<any_subset_name>.txtquery/image_name_1.jpg
bounding_box_<any_subset_name>/image_name_2.jpg
bounding_box_<any_subset_name>/image_name_3.jpg
# image_name = 0001_c1s1_000015_00.jpg0001 - person id
c1 - camera id (there are totally 6 cameras)s1 - sequence
000015 - frame number in sequence
00 - means that this bounding box is the first one among the several
supported annotations: Label market-1501 with attributes (query, person_id, camera_id)
Market-1501 import
Uploaded file: a zip archive of the structure above
supported annotations: Label market-1501 with attributes (query, person_id, camera_id)
‘is_crowd’ (boolean, should be defined for labels as checkbox -es)
Specifies if the annotation label can distinguish between different instances.
If False, the annotation id field encodes the instance id.
Cityscapes export
Downloaded file: a zip archive of the following structure:
label_color.txt a file that describes the color for each label
# label_color.txt example
# r g b label_name
0 0 0 background
0 255 0 tree
...
*_gtFine_color.png class labels encoded by its color.
*_gtFine_labelIds.png class labels are encoded by its index.
*_gtFine_instanceIds.png class and instance labels encoded
by an instance ID. The pixel values encode class and the individual instance:
the integer part of a division by 1000 of each ID provides class ID,
the remainder is the instance ID. If a certain annotation describes multiple
instances, then the pixels have the regular ID of that class
Cityscapes annotations import
Uploaded file: a zip archive with the following structure:
Create a task with the labels you need
or you can use the labels and colors of the original dataset.
To work with the Cityscapes format, you must have a black color label
for the background.
occluded (both UI option and a separate attribute).
Indicates that a significant portion of the object within
the bounding box is occluded by another object
truncated supported only for rectangles
(should be defined for labels as checkbox -es).
Indicates that the bounding box specified for the object
does not correspond to the full extent of the object
‘is_crowd’ supported only for polygons
(should be defined for labels as checkbox -es).
Indicates that the annotation covers multiple instances of the same class
KITTI annotations export
Downloaded file: a zip archive of the following structure:
└─ annotations.zip/
├── label_colors.txt # list of pairs r g b label_name
├── labels.txt # list of labels
└── default/
├── label_2/ # left color camera label files
│ ├── <image_name_1>.txt
│ ├── <image_name_2>.txt
│ └── ...
├── instance/ # instance segmentation masks
│ ├── <image_name_1>.png
│ ├── <image_name_2>.png
│ └── ...
├── semantic/ # semantic segmentation masks (labels are encoded by its id)
│ ├── <image_name_1>.png
│ ├── <image_name_2>.png
│ └── ...
└── semantic_rgb/ # semantic segmentation masks (labels are encoded by its color)
├── <image_name_1>.png
├── <image_name_2>.png
└── ...
KITTI annotations import
You can upload KITTI annotations in two ways:
rectangles for the detection task and
masks for the segmentation task.
For detection tasks the uploading archive should have the following structure:
└─ annotations.zip/
├── labels.txt # optional, labels list for non-original detection labels
└── <subset_name>/
├── label_2/ # left color camera label files
│ ├── <image_name_1>.txt
│ ├── <image_name_2>.txt
│ └── ...
For segmentation tasks the uploading archive should have the following structure:
└─ annotations.zip/
├── label_colors.txt # optional, color map for non-original segmentation labels
└── <subset_name>/
├── instance/ # instance segmentation masks
│ ├── <image_name_1>.png
│ ├── <image_name_2>.png
│ └── ...
├── semantic/ # optional, semantic segmentation masks (labels are encoded by its id)
│ ├── <image_name_1>.png
│ ├── <image_name_2>.png
│ └── ...
└── semantic_rgb/ # optional, semantic segmentation masks (labels are encoded by its color)
├── <image_name_1>.png
├── <image_name_2>.png
└── ...
All annotation files and masks should have structures
that are described in the original format specification.
negative_pairs (should be defined for labels as text):
list of image names with mismatched persons.
positive_pairs (should be defined for labels as text):
list of image names with matched persons.
Import LFW annotation
The uploaded annotations file should be a zip file with the following structure:
<archive_name>.zip/
└── annotations/
├── landmarks.txt # list with landmark points for each image ├── pairs.txt # list of matched and mismatched pairs of person └── people.txt # optional file with a list of persons name
Full information about the content of annotation files is available
here
Export LFW annotation
Downloaded file: a zip archive of the following structure:
On the annotation page:
Upload annotation -> LFW 1.0 -> choose archive with structure
that described in the import section.
2.2.23 - XML annotation format
When you want to download annotations from Computer Vision Annotation Tool (CVAT)
you can choose one of several data formats. The document describes XML annotation format.
Each format has X.Y version (e.g. 1.0). In general the major version (X) is incremented when the data format has
incompatible changes and the minor version (Y) is incremented when the data format is slightly modified
(e.g. it has one or several extra fields inside meta information).
The document will describe all changes for all versions of XML annotation format.
Version 1.1
There are two different formats for images and video tasks at the moment.
The both formats have a common part which is described below. From the previous version flipped tag was added.
Also original_size tag was added for interpolation mode to specify frame size.
In annotation mode each image tag has width and height attributes for the same purpose.
<?xml version="1.0" encoding="utf-8"?><annotations><version>1.1</version><meta><task><id>Number: id of the task</id><name>String: some task name</name><size>Number: count of frames/images in the task</size><mode>String: interpolation or annotation</mode><overlap>Number: number of overlapped frames between segments</overlap><bugtracker>String: URL on an page which describe the task</bugtracker><flipped>Boolean: were images of the task flipped? (True/False)</flipped><created>String: date when the task was created</created><updated>String: date when the task was updated</updated><labels><label><name>String: name of the label (e.g. car, person)</name><attributes><attribute><name>String: attribute name</name><mutable>Boolean: mutable (allow different values between frames)</mutable><input_type>String: select, checkbox, radio, number, text</input_type><default_value>String: default value</default_value><values>String: possible values, separated by newlines
ex. value 2
ex. value 3</values></attribute></attributes></label></labels><segments><segment><id>Number: id of the segment</id><start>Number: first frame</start><stop>Number: last frame</stop><url>String: URL (e.g. http://cvat.example.com/?id=213)</url></segment></segments><owner><username>String: the author of the task</username><email>String: email of the author</email></owner><original_size><width>Number: frame width</width><height>Number: frame height</height></original_size></task><dumped>String: date when the annotation was dumped</dumped></meta> ...
</annotations>
Annotation
Below you can find description of the data format for images tasks.
On each image it is possible to have many different objects. Each object can have multiple attributes.
If an annotation task is created with z_order flag then each object will have z_order attribute which is used
to draw objects properly when they are intersected (if z_order is bigger the object is closer to camera).
In previous versions of the format only box shape was available.
In later releases polygon, polyline, points and tags were added. Please see below for more details:
<?xml version="1.0" encoding="utf-8"?><annotations> ...
<imageid="Number: id of the image (the index in lexical order of images)"name="String: path to the image"width="Number: image width"height="Number: image height"><boxlabel="String: the associated label"xtl="Number: float"ytl="Number: float"xbr="Number: float"ybr="Number: float"occluded="Number: 0 - False, 1 - True"z_order="Number: z-order of the object"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</box><polygonlabel="String: the associated label"points="x0,y0;x1,y1;..."occluded="Number: 0 - False, 1 - True"z_order="Number: z-order of the object"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</polygon><polylinelabel="String: the associated label"points="x0,y0;x1,y1;..."occluded="Number: 0 - False, 1 - True"z_order="Number: z-order of the object"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</polyline><polylinelabel="String: the associated label"points="x0,y0;x1,y1;..."occluded="Number: 0 - False, 1 - True"z_order="Number: z-order of the object"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</polyline><pointslabel="String: the associated label"points="x0,y0;x1,y1;..."occluded="Number: 0 - False, 1 - True"z_order="Number: z-order of the object"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</points><taglabel="String: the associated label"source="manual or auto"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</tag> ...
</image> ...
</annotations>
Below you can find description of the data format for video tasks.
The annotation contains tracks. Each track corresponds to an object which can be presented on multiple frames.
The same object cannot be presented on the same frame in multiple locations.
Each location of the object can have multiple attributes even if an attribute is immutable for the object it will be
cloned for each location (a known redundancy).
<?xml version="1.0" encoding="utf-8"?><annotations> ...
<trackid="Number: id of the track (doesn't have any special meeting"label="String: the associated label"source="manual or auto"><boxframe="Number: frame"xtl="Number: float"ytl="Number: float"xbr="Number: float"ybr="Number: float"outside="Number: 0 - False, 1 - True"occluded="Number: 0 - False, 1 - True"keyframe="Number: 0 - False, 1 - True"><attributename="String: an attribute name">String: the attribute value</attribute> ...
</box><polygonframe="Number: frame"points="x0,y0;x1,y1;..."outside="Number: 0 - False, 1 - True"occluded="Number: 0 - False, 1 - True"keyframe="Number: 0 - False, 1 - True"><attributename="String: an attribute name">String: the attribute value</attribute></polygon><polylineframe="Number: frame"points="x0,y0;x1,y1;..."outside="Number: 0 - False, 1 - True"occluded="Number: 0 - False, 1 - True"keyframe="Number: 0 - False, 1 - True"><attributename="String: an attribute name">String: the attribute value</attribute></polyline><pointsframe="Number: frame"points="x0,y0;x1,y1;..."outside="Number: 0 - False, 1 - True"occluded="Number: 0 - False, 1 - True"keyframe="Number: 0 - False, 1 - True"><attributename="String: an attribute name">String: the attribute value</attribute></points> ...
</track> ...
</annotations>
Many UI elements have shortcut hints. Put your pointer to a required element to see it.
Shortcut
Common
Main functions
F1
Open/hide the list of available shortcuts
F2
Go to the settings page or go back
Ctrl+S
Go to the settings page or go back
Ctrl+Z
Cancel the latest action related with objects
Ctrl+Shift+Z or Ctrl+Y
Cancel undo action
Hold Mouse Wheel
To move an image frame (for example, while drawing)
Player
F
Go to the next frame
D
Go to the previous frame
V
Go forward with a step
C
Go backward with a step
Right
Search the next frame that satisfies to the filters or next frame which contain any objects
Left
Search the previous frame that satisfies to the filters or previous frame which contain any objects
Space
Start/stop automatic changing frames
` or ~
Focus on the element to change the current frame
Modes
N
Repeat the latest procedure of drawing with the same parameters
M
Activate or deactivate mode to merging shapes
Alt+M
Activate or deactivate mode to splitting shapes
G
Activate or deactivate mode to grouping shapes
Shift+G
Reset group for selected shapes (in group mode)
Esc
Cancel any active canvas mode
Image operations
Ctrl+R
Change image angle (add 90 degrees)
Ctrl+Shift+R
Change image angle (subtract 90 degrees)
Shift+B+=
Increase brightness level for the image
Shift+B+-
Decrease brightness level for the image
Shift+C+=
Increase contrast level for the image
Shift+C+-
Decrease contrast level for the image
Shift+S+=
Increase saturation level for the image
Shift+S+-
Increase contrast level for the image
Shift+G+=
Make the grid more visible
Shift+G+-
Make the grid less visible
Shift+G+Enter
Set another color for the image grid
Operations with objects
Ctrl
Switch automatic bordering for polygons and polylines during drawing/editing
Hold Ctrl
When the shape is active and fix it
Alt+Click on point
Deleting a point (used when hovering over a point of polygon, polyline, points)
Shift+Click on point
Editing a shape (used when hovering over a point of polygon, polyline or points)
Right-Click on shape
Display of an object element from objects sidebar
T+L
Change locked state for all objects in the sidebar
L
Change locked state for an active object
T+H
Change hidden state for objects in the sidebar
H
Change hidden state for an active object
Q or /
Change occluded property for an active object
Del or Shift+Del
Delete an active object. Use shift to force delete of locked objects
- or _
Put an active object “farther” from the user (decrease z axis value)
+ or =
Put an active object “closer” to the user (increase z axis value)
Ctrl+C
Copy shape to CVAT internal clipboard
Ctrl+V
Paste a shape from internal CVAT clipboard
Hold Ctrl while pasting
When pasting shape from the buffer for multiple pasting.
Ctrl+B
Make a copy of the object on the following frames
Ctrl+(0..9)
Changes a label for an activated object or for the next drawn object if no objects are activated
Operations are available only for track
K
Change keyframe property for an active track
O
Change outside property for an active track
R
Go to the next keyframe of an active track
E
Go to the previous keyframe of an active track
Attribute annotation mode
Up Arrow
Go to the next attribute (up)
Down Arrow
Go to the next attribute (down)
Tab
Go to the next annotated object in current frame
Shift+Tab
Go to the previous annotated object in current frame
<number>
Assign a corresponding value to the current attribute
Standard 3d mode
Shift+arrrowup
Increases camera roll angle
Shift+arrrowdown
Decreases camera roll angle
Shift+arrrowleft
Decreases camera pitch angle
Shift+arrrowright
Increases camera pitch angle
Alt+O
Move the camera up
Alt+U
Move the camera down
Alt+J
Move the camera left
Alt+L
Move the camera right
Alt+I
Performs zoom in
Alt+K
Performs zoom out
2.2.25 - Filter
Guide to using the Filter feature in CVAT.
There are some reasons to use the feature:
When you use a filter, objects that don’t match the filter will be hidden.
The fast navigation between frames which have an object of interest.
Use the Left Arrow / Right Arrow keys for this purpose
or customize the UI buttons by right-clicking and select switching by filter.
If there are no objects which correspond to the filter,
you will go to the previous / next frame which contains any annotated objects.
To apply filters you need to click on the button on the top panel.
Create a filter
It will open a window for filter input. Here you will find two buttons: Add rule and Add group.
Rules
The Add rule button adds a rule for objects display. A rule may use the following properties:
== - Equally; != - Not equal; > - More; >= - More or equal; < - Less; <= - Less or equal;
Any in; Not in - these operators allow you to set multiple values in one rule;
Is empty; is not empty – these operators don’t require to input a value.
Between; Not between – these operators allow you to choose a range between two values.
Like - this operator indicate that the property must contain a value.
Starts with; Ends with - filter by beginning or end.
Some properties support two types of values that you can choose:
You can add multiple rules, to do so click the add rule button and set another rule.
Once you’ve set a new rule, you’ll be able to choose which operator they will be connected by: And or Or.
All subsequent rules will be joined by the chosen operator.
Click Submit to apply the filter or if you want multiple rules to be connected by different operators, use groups.
Groups
To add a group, click the Add group button. Inside the group you can create rules or groups.
If there is more than one rule in the group, they can be connected by And or Or operators.
The rule group will work as well as a separate rule outside the group and will be joined by an
operator outside the group.
You can create groups within other groups, to do so you need to click the add group button within the group.
You can move rules and groups. To move the rule or group, drag it by the button.
To remove the rule or group, click on the Delete button.
If you activate the Not button, objects that don’t match the group will be filtered out.
Click Submit to apply the filter.
The Cancel button undoes the filter. The Clear filter button removes the filter.
Once applied filter automatically appears in Recent used list. Maximum length of the list is 10.
2.2.26 - Review
Guide to using the Review mode for task validation.
A special mode to check the annotation allows you to point to an object or area in the frame containing an error.
Review mode is not available in 3D tasks.
Review
To conduct a review, you need to change the stage to validation for the desired job on the task page and assign
a user who will conduct the check. Now the job will open in a fashion review. You can also switch to the Review mode
using the UI switcher on the top panel.
Review mode is a UI mode, there is a special Issue tool which you can use to identify objects
or areas in the frame and describe the issue.
To do this, first click Open an issue icon on the controls sidebar:
Then click on a place in the frame to highlight the place or highlight the area by holding the left mouse button
and describe the issue. To select an object, right-click on it and select Open an issue or select one
of several quick issues. The object or area will be shaded in red.
The created issue will appear in the workspace and in the Issues tab on the objects sidebar.
Once all the issues are marked, save the annotation, open the menu and select job state rejected or completed.
After the review, other users will be able to see the issues, comment on each issue
and change the status of the issue to Resolved.
After the issues are fixed select Finish the job from the menu to finish the task.
Or you can switch stage to acceptance on the task page.
Resolve issues
After review, you may see the issues in the Issues tab in the object sidebar.
You can use the arrows on the Issues tab to navigate the frames that contain issues.
In the workspace you can click on issue, you can send a comment on the issue or,
if the issue is resolved, change the status to Resolve.
You can remove the issue by clicking Remove (if your account have the appropriate permissions).
If few issues were created in one place you can access them by hovering over issue and scrolling the mouse wheel.
If the issue is resolved, you can reopen the issue by clicking the Reopen button.
2.2.27 - Context images for 2d task
Adding additional contextual images to a task.
When you create a task, you can provide the images with additional contextual images.
To do this, create a folder related_images and place a folder with a contextual image in it
(make sure the folder has the same name as the image to which it should be tied).
An example of the structure:
root_directory
image_1_to_be_annotated.jpg
image_2_to_be_annotated.jpg
related_images/
image_1_to_be_annotated_jpg/
context_image_for_image_1.jpg
image_2_to_be_annotated_jpg/
context_image_for_image_2.jpg
subdirectory_example/
image_3_to_be_annotated.jpg
related_images/
image_3_to_be_annotated_jpg/
context_image_for_image_3.jpg
The contextual image is displayed in the upper right corner of the workspace.
You can hide it by clicking on the corresponding button or maximize the image by clicking on it.
When the image is maximized, you can rotate it clockwise/counterclockwise and zoom in/out.
You can also move the image by moving the mouse while holding down the LMB
and zoom in/out by scrolling the mouse wheel.
To close the image, just click the X.
2.2.28 - Shape grouping
Grouping multiple shapes during annotation.
This feature allows us to group several shapes.
You may use the Group Shapes button or shortcuts:
G — start selection / end selection in group mode
Esc — close group mode
Shift+G — reset group for selected shapes
You may select shapes clicking on them or selecting an area.
Grouped shapes will have group_id filed in dumped annotation.
Also you may switch color distribution from an instance (default) to a group.
You have to switch Color By Group checkbox for that.
Shapes that don’t have group_id, will be highlighted in white.
2.2.29 - Analytics Monitoring
Using Analytics to monitor usage statistics.
If your CVAT instance was created with analytics support, you can press the Analytics button in the dashboard
and analytics and journals will be opened in a new tab.
The analytics allows you to see how much time every user spends on each task
and how much work they did over any time range.
It also has an activity graph which can be modified with a number of users shown and a timeframe.
2.2.30 - Command line interface (CLI)
Guide to working with CVAT tasks in the command line interface. This section on GitHub.
Description
A simple command line interface for working with CVAT tasks. At the moment it
implements a basic feature set but may serve as the starting point for a more
comprehensive CVAT administration tool in the future.
Overview of functionality:
Create a new task (supports name, bug tracker, project, labels JSON, local/share/remote files)
Delete tasks (supports deleting a list of task IDs)
List all tasks (supports basic CSV or JSON output)
Download JPEG frames (supports a list of frame IDs)
Dump annotations (supports all formats via format string)
Upload annotations for a task in the specified format (e.g. ‘YOLO ZIP 1.0’)
Export and download a whole task
Import a task
Usage
To access the CLI, you need to have python in environment,
as well as a clone of the CVAT repository and the necessary modules:
git clone https://github.com/openvinotoolkit/cvat.git
cd cvat/utils/cli
pip install -r requirements.txt
You will get help with cli.py.
usage: cli.py [-h] [--auth USER:[PASS]] [--server-host SERVER_HOST]
[--server-port SERVER_PORT] [--debug]
{create,delete,ls,frames,dump,upload,export,import} ...
Perform common operations related to CVAT tasks.
positional arguments:
{create,delete,ls,frames,dump,upload,export,import}
optional arguments:
-h, --help show this help message and exit
--auth USER:[PASS] defaults to the current user and supports the PASS
environment variable or password prompt.
--server-host SERVER_HOST
host (default: localhost)
--server-port SERVER_PORT
port (default: 8080)
--https
using https connection (default: False)
--debug show debug output
You can get help for each positional argument, e.g. ls:
cli.py ls -h
usage: cli.py ls [-h] [--json]
List all CVAT tasks in simple or JSON format.
optional arguments:
-h, --help show this help message and exit
--json output JSON data
Create a task named “new task” on the default server “localhost:8080”, labels from the file “labels.json”
and local images “file1.jpg” and “file2.jpg”, the task will be created as current user:
cli.py create "new task" --labels labels.json local file1.jpg file2.jpg
Create a task named “task 1” on the server “example.com” labels from the file “labels.json”
and local image “image1.jpg”, the task will be created as user “user-1”:
Create a task named “task 1 sort random”, with labels “cat” and “dog”, with chunk size 8,
with sorting-method random, frame step 10, copy the data on the CVAT server,
with use zip chunks and the video file will be taken from the shared resource:
Create a task named “task from dataset_1”, labels from the file “labels.json”, with link to bug tracker,
image quality will be reduced to 75, annotation in the format “CVAT 1.1” will be taken
from the file “annotation.xml”, the data will be loaded from “dataset_1/images/”,
the task will be created as user “user-2”, and the password will need to be entered additionally:
Create a task named “segmented task 1”, labels from the file “labels.json”, with overlay size 5,
segment size 100, with frames 5 through 705, using cache and with a remote video file:
Create a task named “task 1 with sync annotation”, with label “person”,
with annotation storage in git repository, enable lfs and the image files from the shared resource:
usage: python create.py [-h][--force][--output-dir .]sourcepositional arguments:
source Source paths
optional arguments:
-h, --help show this help message and exit --force Use this flag to prepare the manifest file for video data if by default the video does not meet the requirements
and a manifest file is not prepared
--output-dir OUTPUT_DIR
Directory where the manifest file will be saved
Data on the fly processing is a way of working with data, the main idea of which is as follows: when creating a task,
the minimum necessary meta information is collected. This meta information allows in the future to create necessary
chunks when receiving a request from a client.
Generated chunks are stored in a cache of the limited size with a policy of evicting less popular items.
When a request is received from a client, the required chunk is searched for in the cache. If the chunk does not exist
yet, it is created using prepared meta information and then put into the cache.
This method of working with data allows:
reduce the task creation time.
store data in a cache of the limited size with a policy of evicting less popular items.
Unfortunately, this method will not work for all videos with a valid manifest file. If there are not enough keyframes
in the video for smooth video decoding, the task will be created in another way. Namely, all chunks will be prepared
during task creation, which may take some time.
Uploading a manifest with data
When creating a task, you can upload a manifest.jsonl file along with the video or dataset with images.
You can see how to prepare it here.
2.2.33 - Serverless tutorial
Introduction
Computers have now become our partners. They help us to solve routine problems,
fix mistakes, find information, etc. It is a natural idea to use their
compute power to annotate datasets. There are multiple DL models for
classification, object detection, semantic segmentation which can do
data annotation for us. And it is relatively simple to integrate your
own ML/DL solution into CVAT.
But the world is not perfect and we don’t have a silver bullet which can
solve all our problems. Usually, available DL models are trained on public
datasets which cannot cover all specific cases. Very often you want to
detect objects which cannot be recognized by these models. Our annotation
requirements can be so strict that automatically
annotated objects cannot be accepted as is, and it is easier to annotate them
from scratch. You always need to keep in mind all these mentioned limitations.
Even if you have a DL solution which can
perfectly annotate 50% of your data, it means that manual work will only be
reduced in half.
When we know that DL models can help us to annotate data faster, the next
question is how to use them? In CVAT all such DL models are implemented
as serverless functions for the Nuclio serverless platform.
And there are multiple implemented functions which can be
found in the serverless directory such as Mask RCNN,
Faster RCNN, SiamMask, Inside Outside Guidance, Deep Extreme Cut, etc.
Follow the installation guide to build and deploy
these serverless functions. See the user guide to
understand how to use these functions in the UI to automatically annotate data.
What is a serverless function and why is it used for automatic annotation
in CVAT? Let’s assume that you have a DL model and want to use it for
AI-assisted annotation. The naive approach is to implement a Python
script which uses the DL model to prepare a file with annotations in a
public format like MS COCO or Pascal VOC.
After that you can upload the annotation file into CVAT. It works but it is
not user-friendly. How to make CVAT run the script for you?
You can pack the script with your DL model into a container which
provides a standard interface for interacting with it. One way to do that is to use
the function as a service approach. Your script becomes a function
inside cloud infrastructure which can be called over HTTP. The Nuclio
serverless platform helps us to implement and manage such functions.
CVAT supports Nuclio out of the box if it is built properly. See
the installation guide for instructions.
Thus if you deploy a serverless function, the CVAT server can see it and call it
with appropriate arguments. Of course there are some tricks how to create
serverless functions for CVAT and we will discuss them in next sections of
the tutorial.
Using builtin DL models in practice
In the tutorial it is assumed that you already have the cloned
CVAT GitHub repo.
To build CVAT with serverless support you need to run docker-compose command
with specific configuration files. In the case it is docker-compose.serverless.yml.
It has necessary instructions how to build and deploy Nuclio platform as a
docker container and enable corresponding support in CVAT.
docker-compose -f docker-compose.yml -f docker-compose.dev.yml -f components/serverless/docker-compose.serverless.yml up -d --build
Name Command State Ports
-------------------------------------------------------------------------------------------------------------
cvat /usr/bin/supervisord Up 8080/tcp
cvat_db docker-entrypoint.sh postgres Up 5432/tcp
cvat_proxy /docker-entrypoint.sh /bin ... Up 0.0.0.0:8080->80/tcp,:::8080->80/tcp
cvat_redis docker-entrypoint.sh redis ... Up 6379/tcp
cvat_ui /docker-entrypoint.sh ngin ... Up 80/tcp
nuclio /docker-entrypoint.sh sh - ... Up (healthy) 80/tcp, 0.0.0.0:8070->8070/tcp,:::8070->8070/tcp
Next step is to deploy builtin serverless functions using Nuclio command
line tool (aka nuctl). It is assumed that you followed
the installation guide and nuctl
is already installed on your operating system. Run the following
command to check that it works. In the beginning you should not have
any deployed serverless functions.
nuctl get functions
No functions found
Let’s see on examples how to use DL models for annotation in different
computer vision tasks.
Tracking using SiamMask
In this use case a user needs to annotate all individual objects on a video as
tracks. Basically for every object we need to know its location on every frame.
First step is to deploy SiamMask. The deployment process
can depend on your operating system. On Linux you can use serverless/deploy_cpu.sh
auxiliary script, but below we are using nuctl directly.
21.05.07 13:00:22.233 nuctl (I) Deploying function {"name": ""}
21.05.07 13:00:22.233 nuctl (I) Building {"versionInfo": "Label: 1.5.16, Git commit: ae43a6a560c2bec42d7ccfdf6e8e11a1e3cc3774, OS: linux, Arch: amd64, Go version: go1.14.3", "name": ""}
21.05.07 13:00:22.652 nuctl (I) Cleaning up before deployment {"functionName": "pth-foolwood-siammask"}
21.05.07 13:00:22.705 nuctl (I) Staging files and preparing base images
21.05.07 13:00:22.706 nuctl (I) Building processor image {"imageName": "cvat/pth.foolwood.siammask:latest"}
21.05.07 13:00:22.706 nuctl.platform.docker (I) Pulling image {"imageName": "quay.io/nuclio/handler-builder-python-onbuild:1.5.16-amd64"}
21.05.07 13:00:26.351 nuctl.platform.docker (I) Pulling image {"imageName": "quay.io/nuclio/uhttpc:0.0.1-amd64"}
21.05.07 13:00:29.819 nuctl.platform (I) Building docker image {"image": "cvat/pth.foolwood.siammask:latest"}
21.05.07 13:00:30.103 nuctl.platform (I) Pushing docker image into registry {"image": "cvat/pth.foolwood.siammask:latest", "registry": ""}
21.05.07 13:00:30.103 nuctl.platform (I) Docker image was successfully built and pushed into docker registry {"image": "cvat/pth.foolwood.siammask:latest"}
21.05.07 13:00:30.104 nuctl (I) Build complete {"result": {"Image":"cvat/pth.foolwood.siammask:latest","UpdatedFunctionConfig":{"metadata":{"name":"pth-foolwood-siammask","namespace":"nuclio","labels":{"nuclio.io/project-name":"cvat"},"annotations":{"framework":"pytorch","name":"SiamMask","spec":"","type":"tracker"}},"spec":{"description":"Fast Online Object Tracking and Segmentation","handler":"main:handler","runtime":"python:3.6","env":[{"name":"PYTHONPATH","value":"/opt/nuclio/SiamMask:/opt/nuclio/SiamMask/experiments/siammask_sharp"}],"resources":{},"image":"cvat/pth.foolwood.siammask:latest","targetCPU":75,"triggers":{"myHttpTrigger":{"class":"","kind":"http","name":"myHttpTrigger","maxWorkers":2,"workerAvailabilityTimeoutMilliseconds":10000,"attributes":{"maxRequestBodySize":33554432}}},"build":{"image":"cvat/pth.foolwood.siammask","baseImage":"continuumio/miniconda3","directives":{"preCopy":[{"kind":"WORKDIR","value":"/opt/nuclio"},{"kind":"RUN","value":"conda create -y -n siammask python=3.6"},{"kind":"SHELL","value":"[\"conda\", \"run\", \"-n\", \"siammask\", \"/bin/bash\", \"-c\"]"},{"kind":"RUN","value":"git clone https://github.com/foolwood/SiamMask.git"},{"kind":"RUN","value":"pip install -r SiamMask/requirements.txt jsonpickle"},{"kind":"RUN","value":"conda install -y gcc_linux-64"},{"kind":"RUN","value":"cd SiamMask \u0026\u0026 bash make.sh \u0026\u0026 cd -"},{"kind":"RUN","value":"wget -P SiamMask/experiments/siammask_sharp http://www.robots.ox.ac.uk/~qwang/SiamMask_DAVIS.pth"},{"kind":"ENTRYPOINT","value":"[\"conda\", \"run\", \"-n\", \"siammask\"]"}]},"codeEntryType":"image"},"platform":{"attributes":{"mountMode":"volume","restartPolicy":{"maximumRetryCount":3,"name":"always"}}},"readinessTimeoutSeconds":60,"securityContext":{},"eventTimeout":"30s"}}}}
21.05.07 13:00:31.387 nuctl.platform (I) Waiting for function to be ready {"timeout": 60}
21.05.07 13:00:32.796 nuctl (I) Function deploy complete {"functionName": "pth-foolwood-siammask", "httpPort": 49155}
nuctl get functions
NAMESPACE | NAME | PROJECT | STATE | NODE PORT | REPLICAS
nuclio | pth-foolwood-siammask | cvat | ready | 49155 | 1/1
Let’s see how it works in the UI. Go to the models tab
and check that you can see SiamMask in the list. If you cannot, it
means that there are some problems. Go to one of our public channels and ask
for help.
After that, go to the new task page and
create a task with this video file. You can choose any task name,
any labels, and even another video file if you like. In this case, the Remote sources
option was used to specify the video file. Press submit button at the end to
finish the process.
Open the task and use AI tools to start tracking
an object. Draw a bounding box around an object, and sequentially switch
through the frame and correct the restrictive box if necessary.
Finally you will get bounding boxes.
SiamMask model is more optimized to work on Nvidia GPUs.
For more information about deploying the model for the GPU, read on.
Object detection using YOLO-v3
First of all let’s deploy the DL model. The deployment process is similar for
all serverless functions. Need to run nuctl deploy command with appropriate
arguments. To simplify the process, you can use serverless/deploy_cpu.sh
command. Inference of the serverless function is optimized for CPU using
Intel OpenVINO framework.
Again, go to models tab and check that you can
see YOLO v3 in the list. If you cannot by a reason it means that there are some
problems. Go to one of our public channels and ask for help.
Let us reuse the task which you created for testing SiamMask serverless function
above. Choose the magic wand tool, go to the Detectors tab, and select
YOLO v3 model. Press Annotate button and after a couple of seconds you
should see detection results. Do not forget to save annotations.
Also it is possible to run a detector for the whole annotation task. Thus
CVAT will run the serverless function on every frame of the task and submit
results directly into database. For more details please read
the guide.
Objects segmentation using Mask-RCNN
If you have a detector, which returns polygons, you can segment objects. One
of such detectors is Mask-RCNN. There are several implementations of the
detector available out of the box:
serverless/openvino/omz/public/mask_rcnn_inception_resnet_v2_atrous_coco is
optimized using Intel OpenVINO framework and works well
if it is run on an Intel CPU.
serverless/tensorflow/matterport/mask_rcnn/ is optimized for GPU.
The deployment process for a serverless function optimized for GPU is similar.
Just need to run serverless/deploy_gpu.sh script. It runs mostly the same
commands but utilize function-gpu.yaml configuration file instead of
function.yaml internally. See next sections if you want to understand the
difference.
Note: Please do not run several GPU functions at the same time. In many cases it
will not work out of the box. For now you should manually schedule different
functions on different GPUs and it requires source code modification. Nuclio
autoscaler does not support the local platform (docker).
Now you should be able to annotate objects using segmentation masks.
Adding your own DL models
Choose a DL model
For the tutorial I will choose a popular AI library with a lot of models inside.
In your case it can be your own model. If it is based on detectron2 it
will be easy to integrate. Just follow the tutorial.
Detectron2 is Facebook AI Research’s next generation
library that provides state-of-the-art detection and segmentation algorithms.
It is the successor of Detectron and maskrcnn-benchmark. It supports a number
of computer vision research projects and production applications in Facebook.
Clone the repository somewhere. I assume that all other experiments will be
run from the cloned detectron2 directory.
git clone https://github.com/facebookresearch/detectron2
cd detectron2
Run local experiments
Let’s run a detection model locally. First of all need to
install requirements for the library.
In my case I have Ubuntu 20.04 with python 3.8.5. I installed
PyTorch 1.8.1 for Linux with pip, python, and CPU inside
a virtual environment. Follow opencv-python
installation guide to get the library for demo and visualization.
Install the detectron2 library from your local clone (you should be inside
detectron2 directory).
python -m pip install -e .
After the library from Facebook AI Research is installed, we can run a couple
of experiments. See the official tutorial for more
examples. I decided to experiment with RetinaNet. First
step is to download model weights.
Next step is to minimize demo/demo.py script and keep code which is necessary to load,
run, and interpret output of the model only. Let’s hard code parameters and remove
argparse. Keep only code which is responsible for working with an image. There is
no common advice how to minimize some code.
Finally you should get something like the code below which has fixed config, read a
predefined image, initialize predictor, and run inference. As the final step it prints
all detected bounding boxes with scores and labels.
When we know how to run the DL model locally, we can prepare a serverless
function which can be used by CVAT to annotate data. Let’s see how function.yaml
will look like…
Let’s look at faster_rcnn_inception_v2_coco serverless
function configuration as an example and try adapting it to our case.
First of all let’s invent an unique name for the new function:
pth.facebookresearch.detectron2.retinanet_r101. Section annotations
describes our function for CVAT serverless subsystem:
annotations.name is a display name
annotations.type is a type of the serverless function. It can have
several different values. Basically it affects input and output of the function.
In our case it has detector type and it means that the integrated DL model can
generate shapes with labels for an image.
annotations.framework is used for information only and can have arbitrary
value. Usually it has values like OpenVINO, PyTorch, TensorFlow, etc.
annotations.spec describes the list of labels which the model supports. In
the case the DL model was trained on MS COCO dataset and the list of labels
correspond to the dataset.
spec.description is used to provide basic information for the model.
Next step is to describe how to build our serverless function:
spec.build.image is the name of your docker image
spec.build.baseImage is the name of a base container image from which to build the function
spec.build.directives are commands to build your docker image
In our case we start from Ubuntu 20.04 base image, install curl to download
weights for our model, git to clone detectron2 project from GitHub, and
python together with pip. Repeat installation steps which we used to setup
the DL model locally with minor modifications.
For Nuclio platform we have to specify a couple of more parameters:
spec.triggers.myHttpTrigger describes HTTP trigger
to handle incoming HTTP requests.
spec.platform describes some important parameters to run your functions like
restartPolicy and mountMode. Read Nuclio documentation for more details.
Next step is to adapt our source code which we implemented to run the DL model
locally to requirements of Nuclio platform. First step is to load the model
into memory using init_context(context) function. Read more about the function
in Best Practices and Common Pitfalls.
After that we need to accept incoming HTTP requests, run inference,
reply with detection results. For the process our entry point is resposible
which we specified in our function specification handler(context, event).
Again in accordance to function specification the entry point should be
located inside main.py.
To use the new serverless function you have to deploy it using nuctl command.
The actual deployment process is described in
automatic annotation guide.
To optimize a function for a specific device (e.g. GPU), basically you just need
to modify instructions above to run the function on the target device. In most
cases it will be necessary to modify installation instructions only.
For RetinaNet R101 which was added above modifications will look like:
Note: GPU has very limited amount of memory and it doesn’t allow to run
multiple serverless functions in parallel for now using free open-source
Nuclio version on the local platform because scaling to zero feature is
absent. Theoretically it is possible to run different functions on different
GPUs, but it requires to change source code on corresponding serverless
functions to choose a free GPU.
Debugging a serverless function
Let’s say you have a problem with your serverless function and want to debug it.
Of course you can use context.logger.info or similar methods to print the
intermediate state of your function.
Another way is to debug using Visual Studio Code.
Please see instructions below to setup your environment step by step.
Let’s modify our function.yaml to include debugpy
package and specify that maxWorkers count is 1. Otherwise both workers will
try to use the same port and it will lead to an exception in python code.
Change main.py to listen to a port (e.g. 5678). Insert code below
in the beginning of your file with entry point.
importdebugpydebugpy.listen(5678)
After these changes deploy the serverless function once again. For
serverless/pytorch/facebookresearch/detectron2/retinanet/nuclio/ you should
run the command below:
To debug python code inside a container you have to publish the port (in this
tutorial it is 5678). Nuclio deploy command doesn’t support that and we have to
workaround it using SSH port forwarding.
Install SSH server on your host machine using sudo apt install openssh-server
In /etc/ssh/sshd_config host file set GatewayPorts yes
Restart ssh service to apply changes using sudo systemctl restart ssh.service
Next step is to install ssh client inside the container and run port forwarding.
In the snippet below instead of user and ipaddress provide username and
IP address of your host (usually IP address starts from 192.168.). You will
need to confirm that you want to connect to your host computer and enter your
password. Keep the terminal open after that.
root@2d6cceec8f70:/opt/nuclio# ssh -R 5678:localhost:5678 nmanovic@192.168.50.188
The authenticity of host '192.168.50.188 (192.168.50.188)' can't be established.
ECDSA key fingerprint is SHA256:0sD6IWi+FKAhtUXr2TroHqyjcnYRIGLLx/wkGaZeRuo.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.50.188' (ECDSA) to the list of known hosts.
nmanovic@192.168.50.188's password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.8.0-53-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
223 updates can be applied immediately.
132 of these updates are standard security updates.
To see these additional updates run: apt list --upgradable
Your Hardware Enablement Stack (HWE) is supported until April 2025.
Last login: Fri Jun 25 16:39:04 2021 from 172.17.0.5
[setupvars.sh] OpenVINO environment initialized
nmanovic@nmanovic-dl-node:~$
Finally, add the configuration below into your launch.json. Open Visual Studio Code and
run Serverless Debug configuration, set a breakpoint in main.py and try to call the
serverless function from CVAT UI. The breakpoint should be triggered in Visual Studio
Code and it should be possible to inspect variables and debug code.
Note: In case of changes in the source code, need to re-deploy the function and initiate
port forwarding again.
Troubleshooting
First of all need to check that you are using the recommended version of
Nuclio framework. In my case it is 1.5.16 but you need to check the
installation manual.
Check that Nuclio dashboard is running and its version corresponds to nuctl.
docker ps --filter NAME=^nuclio$
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7ab0c076c927 quay.io/nuclio/dashboard:1.5.16-amd64 "/docker-entrypoint.…" 6 weeks ago Up 46 minutes (healthy) 80/tcp, 0.0.0.0:8070->8070/tcp, :::8070->8070/tcp nuclio
Be sure that the model, which doesn’t work, is healthy. In my case Inside Outside
Guidance is not running.
docker ps --filter NAME=iog
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Let’s run it. Go to the root of CVAT repository and run the deploying command.
Deploying serverless/pytorch/shiyinzhang/iog function...
21.07.06 12:49:08.763 nuctl (I) Deploying function {"name": ""}
21.07.06 12:49:08.763 nuctl (I) Building {"versionInfo": "Label: 1.5.16, Git commit: ae43a6a560c2bec42d7ccfdf6e8e11a1e3cc3774, OS: linux, Arch: amd64, Go version: go1.14.3", "name": ""}
21.07.06 12:49:09.085 nuctl (I) Cleaning up before deployment {"functionName": "pth.shiyinzhang.iog"}
21.07.06 12:49:09.162 nuctl (I) Function already exists, deleting function containers {"functionName": "pth.shiyinzhang.iog"}
21.07.06 12:49:09.230 nuctl (I) Staging files and preparing base images
21.07.06 12:49:09.232 nuctl (I) Building processor image {"imageName": "cvat/pth.shiyinzhang.iog:latest"}
21.07.06 12:49:09.232 nuctl.platform.docker (I) Pulling image {"imageName": "quay.io/nuclio/handler-builder-python-onbuild:1.5.16-amd64"}
21.07.06 12:49:12.525 nuctl.platform.docker (I) Pulling image {"imageName": "quay.io/nuclio/uhttpc:0.0.1-amd64"}
21.07.06 12:49:16.222 nuctl.platform (I) Building docker image {"image": "cvat/pth.shiyinzhang.iog:latest"}
21.07.06 12:49:16.555 nuctl.platform (I) Pushing docker image into registry {"image": "cvat/pth.shiyinzhang.iog:latest", "registry": ""}
21.07.06 12:49:16.555 nuctl.platform (I) Docker image was successfully built and pushed into docker registry {"image": "cvat/pth.shiyinzhang.iog:latest"}
21.07.06 12:49:16.555 nuctl (I) Build complete {"result": {"Image":"cvat/pth.shiyinzhang.iog:latest","UpdatedFunctionConfig":{"metadata":{"name":"pth.shiyinzhang.iog","namespace":"nuclio","labels":{"nuclio.io/project-name":"cvat"},"annotations":{"framework":"pytorch","min_pos_points":"1","name":"IOG","spec":"","startswith_box":"true","type":"interactor"}},"spec":{"description":"Interactive Object Segmentation with Inside-Outside Guidance","handler":"main:handler","runtime":"python:3.6","env":[{"name":"PYTHONPATH","value":"/opt/nuclio/iog"}],"resources":{},"image":"cvat/pth.shiyinzhang.iog:latest","targetCPU":75,"triggers":{"myHttpTrigger":{"class":"","kind":"http","name":"myHttpTrigger","maxWorkers":2,"workerAvailabilityTimeoutMilliseconds":10000,"attributes":{"maxRequestBodySize":33554432}}},"volumes":[{"volume":{"name":"volume-1","hostPath":{"path":"/home/nmanovic/Workspace/cvat/serverless/common"}},"volumeMount":{"name":"volume-1","mountPath":"/opt/nuclio/common"}}],"build":{"image":"cvat/pth.shiyinzhang.iog","baseImage":"continuumio/miniconda3","directives":{"preCopy":[{"kind":"WORKDIR","value":"/opt/nuclio"},{"kind":"RUN","value":"conda create -y -n iog python=3.6"},{"kind":"SHELL","value":"[\"conda\", \"run\", \"-n\", \"iog\", \"/bin/bash\", \"-c\"]"},{"kind":"RUN","value":"conda install -y -c anaconda curl"},{"kind":"RUN","value":"conda install -y pytorch=0.4 torchvision=0.2 -c pytorch"},{"kind":"RUN","value":"conda install -y -c conda-forge pycocotools opencv scipy"},{"kind":"RUN","value":"git clone https://github.com/shiyinzhang/Inside-Outside-Guidance.git iog"},{"kind":"WORKDIR","value":"/opt/nuclio/iog"},{"kind":"ENV","value":"fileid=1Lm1hhMhhjjnNwO4Pf7SC6tXLayH2iH0l"},{"kind":"ENV","value":"filename=IOG_PASCAL_SBD.pth"},{"kind":"RUN","value":"curl -c ./cookie -s -L \"https://drive.google.com/uc?export=download\u0026id=${fileid}\""},{"kind":"RUN","value":"echo \"/download/ {print \\$NF}\" \u003e confirm_code.awk"},{"kind":"RUN","value":"curl -Lb ./cookie \"https://drive.google.com/uc?export=download\u0026confirm=`awk -f confirm_code.awk ./cookie`\u0026id=${fileid}\" -o ${filename}"},{"kind":"WORKDIR","value":"/opt/nuclio"},{"kind":"ENTRYPOINT","value":"[\"conda\", \"run\", \"-n\", \"iog\"]"}]},"codeEntryType":"image"},"platform":{"attributes":{"mountMode":"volume","restartPolicy":{"maximumRetryCount":3,"name":"always"}}},"readinessTimeoutSeconds":60,"securityContext":{},"eventTimeout":"30s"}}}}
21.07.06 12:49:17.422 nuctl.platform.docker (W) Failed to run container {"err": "stdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n", "errVerbose": "\nError - exit status 125\n /nuclio/pkg/cmdrunner/shellrunner.go:96\n\nCall stack:\nstdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n\n /nuclio/pkg/cmdrunner/shellrunner.go:96\nstdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n", "errCauses": [{"error": "exit status 125"}], "stdout": "1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n", "stderr": ""}
21.07.06 12:49:17.422 nuctl (W) Failed to create a function; setting the function status {"err": "Failed to run a Docker container", "errVerbose": "\nError - exit status 125\n /nuclio/pkg/cmdrunner/shellrunner.go:96\n\nCall stack:\nstdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n\n /nuclio/pkg/cmdrunner/shellrunner.go:96\nFailed to run a Docker container\n /nuclio/pkg/platform/local/platform.go:653\nFailed to run a Docker container", "errCauses": [{"error": "stdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n", "errorVerbose": "\nError - exit status 125\n /nuclio/pkg/cmdrunner/shellrunner.go:96\n\nCall stack:\nstdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n\n /nuclio/pkg/cmdrunner/shellrunner.go:96\nstdout:\n1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb\ndocker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.\n\nstderr:\n", "errorCauses": [{"error": "exit status 125"}]}]}
Error - exit status 125
/nuclio/pkg/cmdrunner/shellrunner.go:96
Call stack:
stdout:
1373cb432a178a3606685b5975e40a0755bc7958786c182304f5d1bbc0873ceb
docker: Error response from daemon: driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (df68e7b4a60e553ee3079f1f1622b050cc958bd50f2cd359a20164d8a417d0ea): Bind for 0.0.0.0:49154 failed: port is already allocated.
stderr:
/nuclio/pkg/cmdrunner/shellrunner.go:96
Failed to run a Docker container
/nuclio/pkg/platform/local/platform.go:653
Failed to deploy function
...//nuclio/pkg/platform/abstract/platform.go:182
NAMESPACE | NAME | PROJECT | STATE | NODE PORT | REPLICAS
nuclio | openvino-dextr | cvat | ready | 49154 | 1/1
nuclio | pth-foolwood-siammask | cvat | ready | 49155 | 1/1
nuclio | pth.facebookresearch.detectron2.retinanet_r101 | cvat | ready | 49155 | 1/1
nuclio | pth.shiyinzhang.iog | cvat | error | 0 | 1/1
In this case the container was built some time ago and the port 49154 was
assigned by Nuclio. Now the port is used by openvino-dextr as we can
see in logs. To prove our hypothesis just need to run a couple of docker
commands:
docker container ls -a | grep iog
eb0c1ee46630 cvat/pth.shiyinzhang.iog:latest "conda run -n iog pr…" 9 minutes ago Created nuclio-nuclio-pth.shiyinzhang.iog
docker inspect eb0c1ee46630 | grep 49154
"Error": "driver failed programming external connectivity on endpoint nuclio-nuclio-pth.shiyinzhang.iog (02384290f91b2216162b1603322dadee426afe7f439d3d090f598af5d4863b2d): Bind for 0.0.0.0:49154 failed: port is already allocated",
"HostPort": "49154"
To solve the problem let’s just remove the previous container for the function.
In this case it is eb0c1ee46630. After that the deploying command works as
expected.
When you investigate an issue with a serverless function, it is extremely
useful to look at logs. Just run a couple of commands like
docker logs <container>.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3b6ef9a9f3e2 cvat/pth.shiyinzhang.iog:latest "conda run -n iog pr…" 4 hours ago Up 4 hours (healthy) 0.0.0.0:49159->8080/tcp, :::49159->8080/tcp nuclio-nuclio-pth.shiyinzhang.iog
docker logs nuclio-nuclio-pth.shiyinzhang.iog
If before model deployment you see that the NODE PORT is 0, you need to assign it manually.
Add the port: 32001 attribute to the function.yaml file of each model, before you deploy the model.
Different ports should be prescribed for different models.
Install git and clone repository on Ubuntu,
as described in the installation manual.
After that, run the commands from this tutorial through Ubuntu.
3 - Administration
This section contains documents for system administrators.
3.1 - Basics
This section contains basic documents for system administrators.
3.1.1 - Installation Guide
A CVAT installation guide for different operating systems.
Quick installation guide
Before you can use CVAT, you’ll need to get it installed. The document below
contains instructions for the most popular operating systems. If your system is
not covered by the document it should be relatively straight forward to adapt
the instructions below for other systems.
Probably you need to modify the instructions below in case you are behind a proxy
server. Proxy is an advanced topic and it is not covered by the guide.
Log out and log back in (or reboot) so that your group membership is
re-evaluated. You can type groups command in a terminal window after
that and check if docker group is in its output.
Install docker-compose (1.19.0 or newer). Compose is a tool for
defining and running multi-container docker applications.
To access CVAT over a network or through a different system, export CVAT_HOST environment variable
exportCVAT_HOST=your-ip-address
Run docker containers. It will take some time to download the latest CVAT
release and other required images like postgres, redis, etc. from DockerHub and create containers.
docker-compose up -d
Alternative: if you want to build the images locally with unreleased changes
run the following command. It will take some time to build CVAT images.
docker-compose -f docker-compose.yml -f docker-compose.dev.yml build
docker-compose up -d
You can register a user but by default it will not have rights even to view
list of tasks. Thus you should create a superuser. A superuser can use an
admin panel to assign correct groups to the user. Please use the command
below:
Open the installed Google Chrome browser and go to localhost:8080.
Type your login/password for the superuser on the login page and press the Login
button. Now you should be able to create a new annotation task. Please read the
CVAT manual for more details.
Windows 10
Install WSL2 (Windows subsystem for Linux) refer to this official guide.
WSL2 requires Windows 10, version 2004 or higher. Note: You may not have to install a Linux distribution unless
needed.
Download and install Docker Desktop for Windows.
Double-click Docker for Windows Installer to run the installer.
More instructions can be found here.
Official guide for docker WSL2 backend can be found
here. Note: Check that you are specifically using WSL2 backend
for Docker.
Download and install
Git for Windows.
When installing the package please keep all options by default.
More information about the package can be found here.
Download and install Google Chrome. It is the only browser
which is supported by CVAT.
Go to windows menu, find Git Bash application and run it. You should see a terminal window.
Run docker containers. It will take some time to download the latest CVAT
release and other required images like postgres, redis, etc. from DockerHub and create containers.
docker-compose up -d
Alternative: if you want to build the images locally with unreleased changes
run the following command. It will take some time to build CVAT images.
docker-compose -f docker-compose.yml -f docker-compose.dev.yml build
docker-compose up -d
You can register a user but by default it will not have rights even to view
list of tasks. Thus you should create a superuser. A superuser can use an
admin panel to assign correct groups to other users. Please use the command
below:
If you don’t have winpty installed or the above command does not work, you may also try the following:
# enter docker image firstdocker exec -it cvat /bin/bash
# then runpython3 ~/manage.py createsuperuser
Choose a username and a password for your admin account. For more information
please read Django documentation.
Open the installed Google Chrome browser and go to localhost:8080.
Type your login/password for the superuser on the login page and press the Login
button. Now you should be able to create a new annotation task. Please read the
CVAT manual for more details.
Mac OS Mojave
Download Docker for Mac.
Double-click Docker.dmg to open the installer, then drag Moby the whale
to the Applications folder. Double-click Docker.app in the Applications
folder to start Docker. More instructions can be found
here.
There are several ways to install Git on a Mac. The easiest is probably to
install the Xcode Command Line Tools. On Mavericks (10.9) or above you can
do this simply by trying to run git from the Terminal the very first time.
git --version
If you don’t have it installed already, it will prompt you to install it.
More instructions can be found here.
Download and install Google Chrome. It
is the only browser which is supported by CVAT.
Open a terminal window. The terminal app is in the Utilities folder in
Applications. To open it, either open your Applications folder, then open
Utilities and double-click on Terminal, or press Command - spacebar to
launch Spotlight and type “Terminal,” then double-click the search result.
Run docker containers. It will take some time to download the latest CVAT
release and other required images like postgres, redis, etc. from DockerHub and create containers.
docker-compose up -d
Alternative: if you want to build the images locally with unreleased changes
run the following command. It will take some time to build CVAT images.
docker-compose -f docker-compose.yml -f docker-compose.dev.yml build
docker-compose up -d
You can register a user but by default it will not have rights even to view
list of tasks. Thus you should create a superuser. A superuser can use an
admin panel to assign correct groups to other users. Please use the command
below:
Choose a username and a password for your admin account. For more information
please read Django documentation.
Open the installed Google Chrome browser and go to localhost:8080.
Type your login/password for the superuser on the login page and press the Login
button. Now you should be able to create a new annotation task. Please read the
CVAT manual for more details.
Advanced Topics
Deploying CVAT behind a proxy
If you deploy CVAT behind a proxy and do not plan to use any of serverless functions
for automatic annotation, the exported environment variables
http_proxy, https_proxy and no_proxy should be enough to build images.
Otherwise please create or edit the file ~/.docker/config.json in the home directory of the user
which starts containers and add JSON such as the following:
These environment variables are set automatically within any container.
Please see the Docker documentation for more details.
Using the Traefik dashboard
If you are customizing the docker compose files and you come upon some unexpected issues, using the Traefik
dashboard might be very useful to see if the problem is with Traefik configuration, or with some of the services.
You can enable the Traefik dashboard by uncommenting the following lines from docker-compose.yml
services:traefik:# Uncomment to get Traefik dashboard# - "--entryPoints.dashboard.address=:8090"# - "--api.dashboard=true"# labels:# - traefik.enable=true# - traefik.http.routers.dashboard.entrypoints=dashboard# - traefik.http.routers.dashboard.service=api@internal# - traefik.http.routers.dashboard.rule=Host(`${CVAT_HOST:-localhost}`)
and if you are using docker-compose.https.yml, also uncomment these lines
services:traefik:command:# Uncomment to get Traefik dashboard# - "--entryPoints.dashboard.address=:8090"# - "--api.dashboard=true"
Note that this “insecure” dashboard is not recommended in production (and if your instance is publicly available);
if you want to keep the dashboard in production you should read Traefik’s
documentation on how to properly secure it.
# Build and run containers with Analytics component support:docker-compose -f docker-compose.yml \
-f components/analytics/docker-compose.analytics.yml up -d --build
The command below stops and removes containers, networks, volumes, and images
created by up.
docker-compose down
Use your own domain
If you want to access your instance of CVAT outside of your localhost (on another domain),
you should specify the CVAT_HOST environment variable, like this:
exportCVAT_HOST=<YOUR_DOMAIN>
Share path
You can use a share storage for data uploading during you are creating a task.
To do that you can mount it to CVAT docker container. Example of
docker-compose.override.yml for this purpose:
version:'3.3'services:cvat:environment:CVAT_SHARE_URL:'Mounted from /mnt/share host directory'volumes:- cvat_share:/home/django/share:rovolumes:cvat_share:driver_opts:type:nonedevice:/mnt/shareo:bind
You can change the share device path to your actual share. For user convenience
we have defined the environment variable $CVAT_SHARE_URL. This variable
contains a text (url for example) which is shown in the client-share browser.
You can mount
your cloud storage as a FUSE and use it later as a share.
Email verification
You can enable email verification for newly registered users.
Specify these options in the
settings file to configure Django allauth
to enable email verification (ACCOUNT_EMAIL_VERIFICATION = ‘mandatory’).
Access is denied until the user’s email address is verified.
ACCOUNT_AUTHENTICATION_METHOD='username'ACCOUNT_CONFIRM_EMAIL_ON_GET=TrueACCOUNT_EMAIL_REQUIRED=TrueACCOUNT_EMAIL_VERIFICATION='mandatory'# Email backend settings for DjangoEMAIL_BACKEND='django.core.mail.backends.smtp.EmailBackend'
Also you need to configure the Django email backend to send emails.
This depends on the email server you are using and is not covered in this tutorial, please see
Django SMTP backend configuration
for details.
Deploy CVAT on the Scaleway public cloud
Please follow
this tutorial
to install and set up remote access to CVAT on a Scaleway cloud instance with data in a mounted object storage bucket.
Deploy secure CVAT instance with HTTPS
Using Traefik, you can automatically obtain TLS certificate for your domain from Let’s Encrypt,
enabling you to use HTTPS protocol to access your website.
To enable this, first set the the CVAT_HOST (the domain of your website) and ACME_EMAIL
(contact email for Let’s Encrypt) environment variables:
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
Or source packages:
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
docker-compose -f docker-compose.yml -f docker-compose.https.yml up -d
3.1.2 - AWS-Deployment Guide
Instructions for deploying CVAT on Nvidia GPU and other AWS machines.
There are two ways of deploying the CVAT.
On Nvidia GPU Machine: Tensorflow annotation feature is dependent on GPU hardware.
One of the easy ways to launch CVAT with the tf-annotation app is to use AWS P3 instances,
which provides the NVIDIA GPU.
Read more about P3 instances here.
Overall setup instruction is explained in main readme file,
except Installing Nvidia drivers.
So we need to download the drivers and install it.
For Amazon P3 instances, download the Nvidia Drivers from Nvidia website.
For more check Installing the NVIDIA Driver on Linux Instances
link.
For any of above, don’t forget to set the CVAT_HOST environemnt variable to the exposed
AWS public IP address or hostname:
exportCVAT_HOST=your-instance.amazonaws.com
In case of problems with using hostname, you can also use the public IPV4 instead of hostname.
For AWS or any cloud based machines where the instances need to be terminated or stopped,
the public IPV4 and hostname changes with every stop and reboot.
To address this efficiently, avoid using spot instances that cannot be stopped,
since copying the EBS to an AMI and restarting it throws problems.
On the other hand, when a regular instance is stopped and restarted,
the new hostname/IPV4 can be used to set the CVAT_HOST environment variable.
3.1.3 - REST API guide
Instructions on how to interact with REST API and getting swagger documentation.
To access swagger documentation you need to be authorized.
Automatically generated Swagger documentation for Django REST API is available
on <cvat_origin>/api/swagger(default: localhost:8080/api/swagger).
Swagger documentation is visible on allowed hosts, Update environment
variable in docker-compose.yml file with cvat hosted machine IP or domain
name. Example - ALLOWED_HOSTS: 'localhost, 127.0.0.1'.
Make a request to a resource stored on a server and the server will respond with the requested information.
The HTTP protocol is used to transport a data.
Requests are divided into groups:
auth - user authorization queries
comments - requests to post/delete comments to issues
issues - update, delete and view problem comments
jobs -requests to manage the job
lambda - requests to work with lambda function
projects - project management queries
restrictions - requests for restrictions
reviews -adding and removing the review of the job
server - server information requests
tasks - requests to manage tasks
users - user management queries
Besides it contains Models.
Models - the data type is described using a
schema object.
Each group contains queries related to a different types of HTTP methods such as: GET, POST, PATCH, DELETE, etc.
Different methods are highlighted in different color. Each item has a name and description.
Clicking on an element opens a form with a name, description and settings input field or an example of json values.
[{"from":"now/d","to":"now/d","display":"Today","section":0},{"from":"now/w","to":"now/w","display":"This week","section":0},{"from":"now/M","to":"now/M","display":"This month","section":0},{"from":"now/y","to":"now/y","display":"This year","section":0},{"from":"now/d","to":"now","display":"Today so far","section":2},{"from":"now/w","to":"now","display":"Week to date","section":2},{"from":"now/M","to":"now","display":"Month to date","section":2},{"from":"now/y","to":"now","display":"Year to date","section":2},{"from":"now-1d/d","to":"now-1d/d","display":"Yesterday","section":1},{"from":"now-1w/w","to":"now-1w/w","display":"Previous week","section":1},{"from":"now-1m/m","to":"now-1m/m","display":"Previous month","section":1},{"from":"now-1y/y","to":"now-1y/y","display":"Previous year","section":1}]
3.2.2 - Semi-automatic and Automatic Annotation
Information about the installation of components needed for semi-automatic and automatic annotation.
⚠ WARNING: Do not use docker-compose up
If you did, make sure all containers are stopped by docker-compose down.
To bring up cvat with auto annotation tool, from cvat root directory, you need to run:
docker-compose -f docker-compose.yml -f components/serverless/docker-compose.serverless.yml up -d
If you did any changes to the docker-compose files, make sure to add --build at the end.
To stop the containers, simply run:
docker-compose -f docker-compose.yml -f components/serverless/docker-compose.serverless.yml down
You have to install nuctl command line tool to build and deploy serverless
functions. Download version 1.5.16.
It is important that the version you download matches the version in
docker-compose.serverless.yml.
For example, using wget.
Create cvat project inside nuclio dashboard where you will deploy new serverless functions
and deploy a couple of DL models. Commands below should be run only after CVAT has been installed
using docker-compose because it runs nuclio dashboard which manages all serverless functions.
You will need to install Nvidia Container Toolkit.
Also you will need to add --resource-limit nvidia.com/gpu=1 --triggers '{"myHttpTrigger": {"maxWorkers": 1}}' to
the nuclio deployment command. You can increase the maxWorker if you have enough GPU memory.
As an example, below will run on the GPU:
nuctl deploy --project-name cvat \
--path serverless/tensorflow/matterport/mask_rcnn/nuclio \
--platform local --base-image tensorflow/tensorflow:1.15.5-gpu-py3 \
--desc "GPU based implementation of Mask RCNN on Python 3, Keras, and TensorFlow."\
--image cvat/tf.matterport.mask_rcnn_gpu \
--triggers '{"myHttpTrigger": {"maxWorkers": 1}}'\
--resource-limit nvidia.com/gpu=1
Note:
The number of GPU deployed functions will be limited to your GPU memory.
For some models (namely SiamMask) you need an Nvidia driver
version greater than or equal to 450.80.02.
Note for Windows users:
If you want to use nuclio under Windows CVAT installation you should install Nvidia drivers for WSL according to
this instruction and follow the steps up to “2.3 Installing Nvidia drivers”.
Important requirement: you should have the latest versions of Docker Desktop, Nvidia drivers for WSL,
and the latest updates from the Windows Insider Preview Dev channel.
Troubleshooting Nuclio Functions:
You can open nuclio dashboard at localhost:8070.
Make sure status of your functions are up and running without any error.
Test your deployed DL model as a serverless function. The command below should work on Linux and Mac OS.
To check for internal server errors, run docker ps -a to see the list of containers.
Find the container that you are interested, e.g., nuclio-nuclio-tf-faster-rcnn-inception-v2-coco-gpu.
Then check its logs by docker logs <name of your container>
e.g.,
To debug a code inside a container, you can use vscode to attach to a container instructions.
To apply your changes, make sure to restart the container.
docker restart <name_of_the_container>
3.2.3 - Mounting cloud storage
Instructions on how to mount AWS S3 bucket, Microsoft Azure container or Google Drive as a filesystem.
Create a bash script named aws_s3_fuse(e.g in /usr/bin, as root) with this content
(replace user_name on whose behalf the disk will be mounted, backet_name, mount_point, /path/to/.passwd-s3fs):
Create configuration file connection.cfg with same content, change accountName,
select one from accountKey or sasToken and replace with your value:
accountName <account-name-here>
# Please provide either an account key or a SAS token, and delete the other line.accountKey <account-key-here-delete-next-line>
#change authType to specify only 1sasToken <shared-access-token-here-delete-previous-line>
authType <MSI/SAS/SPN/Key/empty>
containerName <insert-container-name-here>
Create a bash script named azure_fuse(e.g in /usr/bin, as root) with content below
(replace user_name on whose behalf the disk will be mounted, mount_point, /path/to/blobfusetmp,/path/to/connection.cfg):
This command will create the default application directory (~/.gdfuse/default),
containing the configuration file config (see the wiki
page for more details about configuration).
And it will start a web browser to obtain authorization to access your Google Drive.
This will let you modify default configuration before mounting the filesystem.
Then you can choose a local directory to mount your Google Drive (e.g.: ~/GoogleDrive).
Create the mount point, if it doesn’t exist(replace mount_point):
mountpoint="<mount_point>"mkdir -p $mountpoint
Uncomment user_allow_other in the /etc/fuse.conf file: sudo nano /etc/fuse.conf
Create a bash script named gdfuse(e.g in /usr/bin, as root) with this content
(replace user_name on whose behalf the disk will be mounted, label, mount_point):
Instructions on how to backup CVAT data with Docker.
About CVAT data volumes
Docker volumes are used to store all CVAT data:
cvat_db: PostgreSQL database files, used to store information about users, tasks, projects, annotations, etc.
Mounted into cvat_db container by /var/lib/postgresql/data path.
cvat_data: used to store uploaded and prepared media data.
Mounted into cvat container by /home/django/data path.
cvat_logs: used to store logs of CVAT backend processes managed by supevisord.
Mounted into cvat container by /home/django/logs path.
cvat_events: this is an optional volume that is used only when Analytics component
is enabled and is used to store Elasticsearch database files.
Mounted into cvat_elasticsearch container by /usr/share/elasticsearch/data path.
How to backup all CVAT data
All CVAT containers should be stopped before backup:
docker-compose stop
Please don’t forget to include all the compose config files that were used in the docker-compose command
using the -f parameter.
Backup data:
mkdir backup
docker run --rm --name temp_backup --volumes-from cvat_db -v $(pwd)/backup:/backup ubuntu tar -cjvf /backup/cvat_db.tar.bz2 /var/lib/postgresql/data
docker run --rm --name temp_backup --volumes-from cvat -v $(pwd)/backup:/backup ubuntu tar -cjvf /backup/cvat_data.tar.bz2 /home/django/data
# [optional]docker run --rm --name temp_backup --volumes-from cvat_elasticsearch -v $(pwd)/backup:/backup ubuntu tar -cjvf /backup/cvat_events.tar.bz2 /usr/share/elasticsearch/data
Make sure the backup archives have been created, the output of ls backup command should look like this:
ls backup
cvat_data.tar.bz2 cvat_db.tar.bz2 cvat_events.tar.bz2
How to restore CVAT from backup
Warning: use exactly the same CVAT version to restore DB. Otherwise
it will not work because between CVAT releases the layout of DB can be
changed. You always can upgrade CVAT later. It will take care to migrate
your data properly internally.
Note: CVAT containers must exist (if no, please follow the installation guide).
Stop all CVAT containers:
docker-compose stop
Restore data:
cd <path_to_backup_folder>
docker run --rm --name temp_backup --volumes-from cvat_db -v $(pwd):/backup ubuntu bash -c "cd /var/lib/postgresql/data && tar -xvf /backup/cvat_db.tar.bz2 --strip 4"docker run --rm --name temp_backup --volumes-from cvat -v $(pwd):/backup ubuntu bash -c "cd /home/django/data && tar -xvf /backup/cvat_data.tar.bz2 --strip 3"# [optional]docker run --rm --name temp_backup --volumes-from cvat_elasticsearch -v $(pwd):/backup ubuntu bash -c "cd /usr/share/elasticsearch/data && tar -xvf /backup/cvat_events.tar.bz2 --strip 4"
This section contains documents for CVAT developers.
Please take a moment to review this document in order to make the contribution
process easy and effective for everyone involved.
Following these guidelines helps to communicate that you respect the time of
the developers managing and developing this open source project. In return,
they should reciprocate that respect in addressing your issue or assessing
patches and features.
4.1 - Development environment
Installing a development environment for different operating systems.
If you have any problems with installing dependencies from
cvat/requirements/*.txt, you may need to reinstall your system python
In some cases after system update it can be configured incorrectly and cannot compile some native modules
Create a super user for CVAT:
python manage.py createsuperuser
Install npm packages for UI (run the following command from CVAT root directory):
npm ci
Note for Mac users
If you faced with error
Node Sass does not yet support your current environment: OS X 64-bit with Unsupported runtime (57)
Following this guide install Ubuntu 18.04 Linux distribution for WSL.
Run Ubuntu using start menu link or execute next command
wsl-dUbuntu-18.04
Run all commands from this installation guide in WSL Ubuntu shell.
You might have to manually start the redis server in wsl before you can start the configuration inside
Visual Studio Code. You can do this with sudo service redis-server start. Alternatively you can also
use a redis docker image instead of using the redis-server locally.
4.2 - Setup additional components in development environment
Deploying a DL model as a serverless function and Cypress tests.
You have to install nuctl command line tool to build and deploy serverless
functions.
The simplest way to explore Nuclio is to run its graphical user interface (GUI)
of the Nuclio dashboard. All you need in order to run the dashboard is Docker. See
nuclio documentation
for more details.
Create cvat project inside nuclio dashboard where you will deploy new
serverless functions and deploy a couple of DL models.
Information about JavaScript/Typescript coding style that is used in CVAT development.
We use the Airbnb JavaScript Style Guide for JavaScript code with a
little exception - we prefer 4 spaces for indentation of nested blocks and statements.
4.4 - Branching model
Information about the branching model that is used in the project.
origin/master to be the main branch where the source code of
HEAD always reflects a production-ready state
origin/develop to be the main branch where the source code of
HEAD always reflects a state with the latest delivered development
changes for the next release. Some would call this the “integration branch”.
4.5 - Using the issue tracker
Information and rules for using the issue tracker.
Please do not use the issue tracker for personal support requests (use
Stack Overflow).
Please do not derail or troll issues. Keep the discussion on topic and
respect the opinions of others.
4.6 - Bug reports
Guidelines and an example of how to report a bug.
A bug is a demonstrable problem that is caused by the code in the repository.
Good bug reports are extremely helpful - thank you!
Guidelines for bug reports:
Use the GitHub issue search — check if the issue has already been
reported.
Check if the issue has been fixed — try to reproduce it using the
latest develop branch in the repository.
Isolate the problem — ideally create a reduced test case.
A good bug report shouldn’t leave others needing to chase you up for more
information. Please try to be as detailed as possible in your report. What is
your environment? What steps will reproduce the issue? What browser(s) and OS
experience the problem? What would you expect to be the outcome? All these
details will help people to fix any potential bugs.
Example:
Short and descriptive example bug report title
A summary of the issue and the browser/OS environment in which it occurs. If
suitable, include the steps required to reproduce the bug.
This is the first step
This is the second step
Further steps, etc.
Any other information you want to share that is relevant to the issue being
reported. This might include the lines of code that you have identified as
causing the bug, and potential solutions (and your opinions on their
merits).
4.7 - Feature requests
Information on requesting new features.
Feature requests are welcome. But take a moment to find out whether your idea
fits with the scope and aims of the project. It’s up to you to make a strong
case to convince the project’s developers of the merits of this feature. Please
provide as much detail and context as possible.
4.8 - Pull requests
Instructions on how to create a pull request.
Good pull requests - patches, improvements, new features - are a fantastic
help. They should remain focused in scope and avoid containing unrelated
commits.
Please ask first before embarking on any significant pull request (e.g.
implementing features, refactoring code, porting to a different language),
otherwise you risk spending a lot of time working on something that the
project’s developers might not want to merge into the project.
Please adhere to the coding conventions used throughout a project (indentation,
accurate comments, etc.) and any other requirements (such as test coverage).
Follow this process if you’d like your work considered for inclusion in the
project:
Fork the project, clone your fork,
and configure the remotes:
# Clone your fork of the repo into the current directorygit clone https://github.com/<your-username>/<repo-name>
# Navigate to the newly cloned directorycd <repo-name>
# Assign the original repo to a remote called "upstream"git remote add upstream https://github.com/<upstream-owner>/<repo-name>
If you cloned a while ago, get the latest changes from upstream:
Create a new topic branch (off the main project development branch) to
contain your feature, change, or fix:
git checkout -b <topic-branch-name>
Commit your changes in logical chunks. Please adhere to these git commit
message guidelines
or your code is unlikely be merged into the main project. Use Git’s
interactive rebase
feature to tidy up your commits before making them public.
Locally merge (or rebase) the upstream development branch into your topic branch:
file extension. For the importer it can be a comma-separated list.
These parameters are combined to produce a visible name. It can be
set explicitly by the display_name argument.
Importer arguments:
file_object - a file with annotations or dataset
task_data - an instance of TaskData class.
Exporter arguments:
file_object - a file for annotations or dataset
task_data - an instance of TaskData class.
options - format-specific options. save_images is the option to
distinguish if dataset or just annotations are requested.
TaskData provides
many task properties and interfaces to add and read task annotations.
TaskData. shapes - property, an iterator over LabeledShape objects
TaskData. tracks - property, an iterator over Track objects
TaskData. tags - property, an iterator over Tag objects
TaskData. meta - property, a dictionary with task information
TaskData. group_by_frame() - method, returns
an iterator over Frame objects, which groups annotation objects by frame.
Note that TrackedShape s will be represented as LabeledShape s.
TaskData. add_tag(tag) - method,
tag should be an instance of the Tag class
TaskData. add_shape(shape) - method,
shape should be an instance of the Shape class
TaskData. add_track(track) - method,
track should be an instance of the Track class
Sample exporter code:
...# dump meta info if necessary...# iterate over all framesforframe_annotationintask_data.group_by_frame():# get frame infoimage_name=frame_annotation.nameimage_width=frame_annotation.widthimage_height=frame_annotation.height# iterate over all shapes on the frameforshapeinframe_annotation.labeled_shapes:label=shape.labelxtl=shape.points[0]ytl=shape.points[1]xbr=shape.points[2]ybr=shape.points[3]# iterate over shape attributesforattrinshape.attributes:attr_name=attr.nameattr_value=attr.value...# dump annotation codefile_object.write(...)...
Information on using the REST API scheme and principles of its design.
REST API scheme
Common scheme for our REST API is <VERB> [namespace] <objects> <id> <action>.
VERB can be POST, GET, PATCH, PUT, DELETE.
namespace should scope some specific functionality like auth, lambda.
It is optional in the scheme.
Typical objects are tasks, projects, jobs.
When you want to extract a specific object from a collection, just specify its id.
An action can be used to simplify REST API or provide an endpoint for entities
without objects endpoint like annotations, data, data/meta. Note: action
should not duplicate other endpoints without a reason.
Design principles
Use nouns instead of verbs in endpoint paths. For example,
POST /api/tasks instead of POST /api/tasks/create.
Accept and respond with JSON whenever it is possible
Name collections with plural nouns (e.g. /tasks, /projects)
Try to keep the API structure flat. Prefer two separate endpoints
for /projects and /tasks instead of /projects/:id1/tasks/:id2. Use
filters to extract necessary information like /tasks/:id2?project=:id1.
In some cases it is useful to get all tasks. If the structure is
hierarchical, it cannot be done easily. Also you have to know both :id1
and :id2 to get information about the task.
Note: for now we accept GET /tasks/:id2/jobs but it should be replaced
by /jobs?task=:id2 in the future.
Handle errors gracefully and return standard error codes (e.g. 201, 400)
Allow filtering, sorting, and pagination
Maintain good security practices
Cache data to improve performance
Versioning our APIs. It should be done when you delete an endpoint or modify
its behaviors. Versioning uses a schema with Accept header with vendor media type.
Before updating, please follow the backup guide
and backup all CVAT volumes.
To update CVAT, you should clone or download the new version of CVAT and rebuild the CVAT docker images as usual.
docker-compose build
and run containers:
docker-compose up -d
Sometimes the update process takes a lot of time due to changes in the database schema and data.
You can check the current status with docker logs cvat.
Please do not terminate the migration and wait till the process is complete.
Kibana app works, but no logs are displayed
Make sure there aren’t error messages from Elasticsearch:
docker logs cvat_elasticsearch
If you see errors like this:
lood stage disk watermark [95%] exceeded on [uMg9WI30QIOJxxJNDiIPgQ][uMg9WI3][/usr/share/elasticsearch/data/nodes/0] free: 116.5gb[4%], all indices on this node will be marked read-only
To change the hostname, simply set the CVAT_HOST environemnt variable
exportCVAT_HOST=<YOUR_HOSTNAME_OR_IP>
NOTE, if you’re using docker-compose with sudo to run CVAT, then please add the -E (or --preserve-env)
flag to preserve the user environment variable which set above to take effect in your docker containers:
sudo -E docker-compose up -d
If you want to change the default web application port, change the ports part of traefik service configuration
in docker-compose.yml
Note that changing the port does not make sense if you are using HTTPS - port 443 is conventionally
used for HTTPS connections, and is needed for Let’s Encrypt TLS challenge.
How to configure connected share folder on Windows
Follow the Docker manual and configure the directory that you want to use as a shared directory:
The uploaded data is stored in the cvat_data docker volume:
volumes:- cvat_data:/home/django/data
Where are annotations stored
Annotations are stored in the PostgreSQL database. The database files are stored in the cvat_db docker volume:
volumes:- cvat_db:/var/lib/postgresql/data
How to mark job/task as completed
The status is set by the user in the Info window
of the job annotation view.
There are three types of status: annotation, validation or completed.
The status of the job changes the progress bar of the task.
How to upload annotations to an entire task from UI when there are multiple jobs in the task
You can upload annotation for a multi-job task from the Dasboard view or the Task view.
Uploading of annotation from the Annotation view only affects the current job.
How to specify multiple hostnames
To do this, you will need to edit traefik.http.<router>.cvat.rule docker label for both the
cvat and cvat_ui services, like so
(see the documentation on Traefik rules for more details):